
Bespoke, at Scale
A Conversation with Surojit Chatterjee

For decades, we’ve accepted a basic tradeoff: products scale, customization does not.
The beauty of software is its near-zero marginal cost. Build one product, ship it to millions. But tailoring a product to each individual customer used to mean extra code and one-off integrations, expenses that grow linearly with each new client.
AI is upending this tradeoff. The marginal cost of customization is falling precipitously.
When software can reshape itself around each organization – learn its processes, adapt with user feedback – customization becomes the product.
Companies can now sell bespoke, at scale.
Surojit Chatterjee was early to this shift. He’s the founder and CEO of Ema, a platform that builds autonomous AI employees for large companies like Hitachi and ADP.
Before Ema, Surojit joined Coinbase as their Chief Product Officer through its 2021 IPO. He also spent over a decade at Google, scaling Shopping and Mobile Ads into multi-billion dollar businesses.
He and the team built Ema on two core technologies. Their Generative Workflow Engine (GWE) takes organizational goals, assembles specialized sub-agents to pursue them, and orchestrates execution in real-time. Underneath that sits EmaFusion, a routing layer that matches each task to the best model across 100+ LLMs.
Surojit has spent years helping large organizations deploy AI. As agentic systems move from demos to large-scale workloads, I wanted his perspective as someone who has seen the adoption curve firsthand.
What struck me in our conversation was how much traditional software has constrained our thinking. There are countless startups falling into the trap of running the SaaS playbook on top of a fundamentally different product and unit economic model.
Surojit left me with a clearer picture of how AI is actually being deployed today. And with some optimism that these systems, if managed well, can free people to pursue more meaningful work.

01 | “Custom experiences are the product.”
EO: One of the biggest bottlenecks in AI adoption right now is discovery. Customers know AI is powerful. But they don’t have a clear mental model for which tasks can reliably be handed to an agent or how to fold that agent into a preexisting workflow.
How do you handle discovery? Walk me through what happens when Ema sits down with a new customer.
SC: Customers typically come in with some preconceived ideas about how they want to implement AI. We try to get them to think more holistically, and so we rarely end up building their first request.
We start with what we call an Agentic Clinic, a half-day session with stakeholders to map their business processes and identify where AI can have an impact. At the end of the Clinic, we align around two or three high-priority opportunities.
Within 24-48 hours, we build a working prototype for one of those workflows, often with some ready-made components from our platform. That turnaround speed matters, because seeing AI work in practice is what customers usually respond to.
From there, we connect the prototype to their actual data and show them how the agents run in their environment.
So how do you get customers thinking beyond their priors, to think more broadly about what AI is capable of delivering?
Probably best to answer this with an example.
We were working with a Fortune 500 CHRO who wanted to rethink performance management. She had an existing software tool, built around collecting data and conducting reviews across the company. That process was onerous so they only ran it every six months.
At first, she asked us to build an agentic replacement. Same workflow, just automated.
We told her: “Don’t think about replacing your existing tool. Think about reimagining the entire process.”
With AI, you can now give employees feedback daily. You can read code commits live, to assess the productivity of the engineering team. You can give sales reps on-demand coaching by interpreting CRM data and call transcripts.
We were able to build and deploy this new feedback system quickly across 500,000 human employees. The company went from reviews every six months to real-time coaching.
That’s performance management reimagined with AI. Those opportunities exist across every enterprise function.
Performance management is an interesting example because it’s inherently bespoke. OKRs, performance criteria, review cycles… these are unique to each company’s operations and culture.
How do you make sure those nuances don’t get lost when you hand work over to agents?
This is a really important point. With AI, custom experiences are no longer services. Custom experiences are the product.
Think about it like this. In the past, if you wanted clothing that fit perfectly, you went to a tailor. It was expensive and took months, but the result was great. Then manufacturing brought ready-made clothes to market. Off-the-rack items don’t always fit perfectly, but they are instant and cheap.
SaaS is ready-made clothing. It doesn’t quite fit. So we layer on humans and custom builds to act as glue between what the product does and what the business needs.
Now, imagine tailor-made clothes that are instant and cheaper than off-the-rack. You’d never buy off-the-rack again. That’s how AI is changing software.
AI agents are becoming the glue between the tooling and workflows. You tell the AI – “This is how I want performance management to work. Pull data from these systems. Synthesize it this way.”
It takes weeks to build, not months. And once deployed, these systems continue to watch which suggestions humans accept and reject. So the software adapts. It gets more sticky to your organization over time.
So it sounds like one big difference between deploying SaaS versus AI is the degree of iteration. With AI, you start with a baseline, people use it, and the system improves through use.
As a product manager, how do you get the customer to go on that journey? How do you prevent churn, when full functionality isn’t apparent upfront?
You have to deliver impact right away. The customer needs to see the customization and ROI immediately.
Deploying Salesforce or Workday inside a large organization can take months because of all the required integration work. With AI we can deploy equivalent functionality in weeks.
But to drive retention in AI, the software needs to keep delivering magic moments. And it needs to do so on the customer’s timeline, not the vendor’s.
I’ll give you another example.
We have a customer with 250,000 employees across 65 countries. They use Ema for the entire employee lifecycle. Managing travel, employee verification, visa letters, tax forms, and so on.
Before Ema, employees were navigating over 100 SaaS applications for these workflows. I’m not kidding! Layers and layers of software to complete the simplest task.
All of that was instantly abstracted away into a UI that Ema generates on the fly. But we also designed the system to be extensible by the user. Our agents can generate new workflows using natural language.
So every few weeks, we’re seeing new capabilities added by the employees themselves. Not because we shipped an update, but because the users prompted the system to handle something new.
There’s a natural mechanism in the product – this extensibility – that keeps these magic moments coming.
02 | Don’t let agents go rogue
If employees can build new workflows on their own, that changes the role of the software vendor.
You’re no longer building all the features. But you are responsible for the system’s boundaries, so that the AI stays aligned with its intended purpose.
That’s a tricky product challenge. Because in any enterprise agents will have competing goals.
For example, a support agent needs to balance customer satisfaction with cost control.
You don’t want the agent going rogue, approving out-of-policy refunds willy-nilly. But you also don’t want it so constrained that it follows a rigid set of refund rules, and churns the customer.
How do you balance deterministic1 guardrails with the non-deterministic judgment that makes agents valuable?
We deploy a hybrid model.
Our AI systems are designed as a chain of specialized agents working together. Agent A completes a task and passes its output to Agent B, who passes to Agent C, and so on.
Broadly speaking, the handoffs between agents – which agent works on what, in what order – are coded rules. But what each agent does within each step is non-deterministic. Meaning the AI can exercise its own reasoning to deal with ambiguity and variation within its scoped task.
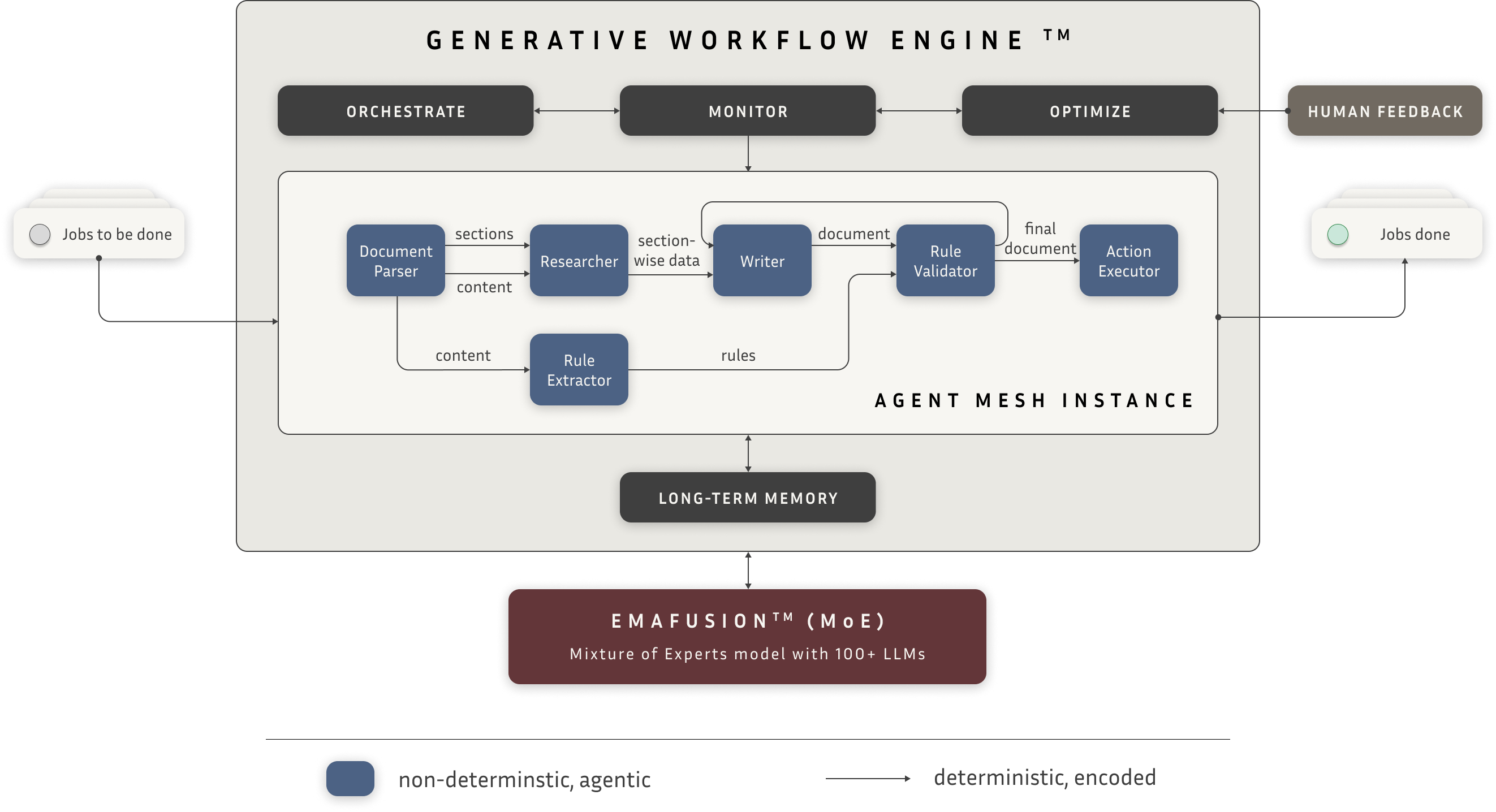
Source: https://www.ema.ai/blog/agentic-ai/generative-workflow-engine-building-emas-brain
This architecture lets us track which sequences work best. And when a given execution path works consistently – a human approves the outcome, a ticket resolves cleanly – we feed that pattern into what we call procedural memory, part of the company’s long-term memory layer.
So the deterministic components – the order of operations, which agent handles which step – provide the guardrails. But within each step, the agent is still reasoning independently.
As model capabilities improve, the boundary between what should be deterministic and non-deterministic is constantly shifting.
How do your developers stay current, to continue to strike the right balance between determinism and non-determinism in the product?
That’s a very evolved question, a very important question that gets into the crux of building AI-native products.
Our goal is to build less determinism in the system over time. Every hardcoded step means more maintenance. We’d rather hand off a decision to an LLM – if we are confident it can handle that decision reliably – than rewrite the code as new edge cases pop up.
We have a small model called EmaFusion that helps us calibrate how much determinism is needed at any point in time. It dynamically assesses the capabilities of every major LLM. When a new version of Claude or Gemini drops, or a new open-source model appears, EmaFusion experiments with different model combinations to see which performs best on a specific task.
This gives us good visibility into what types of work models can reasonably handle and where they fall short and need more hard-coded logic.
03 | The model wars
What’s cool about EmaFusion is you have unique visibility into the relative performance of all major AI models, in real production environments.
Play the model wars out a year or two.
What do you think the landscape looks like? For example, will models converge2? Will open-weight models gain or lose market share?
I think the frontier models – Gemini, Claude – will asymptotically converge in terms of raw capabilities and price. On a benchmark like HLE3, everyone will score about the same.
But on actual enterprise tasks – accounts receivable optimization, policy document synthesis – you’ll see real differences among models. App builders will need to factor those in.
We’re at an important moment in model development.
As production scales, models will optimize further around the tasks they’re already good at, the data their customers continue to give them access to, and the business models they see working.
From what I can see, ChatGPT skews toward consumer. Claude skews enterprise. Gemini wants to play in both, and Google has a ton of data to let them do that. And those starting points may influence where capabilities move over time.
At Ema, our product is built on the premise that there will always be a complex ecosystem of models, each with their own tendencies and capabilities.
One model might be more encouraging, another more cautious. One stronger at coding, another at summarization.
By routing across many different models, we can average out those individual quirks. So the system isn’t overly influenced by any single model’s biases, and the enterprise gets consistent output.
In your data, anything you’re seeing that defies market consensus, that goes against what most believe about these providers?
When I look at the dynamic trace – which models EmaFusion selects for each subtask – there is no “winning” model it consistently favors.
And often, the cutting edge model is not the best choice. For example, for parsing a 30,000 page PDF, a small OCR4 model we built internally outperforms Claude.
04 | Sell simplicity
Today, there are hundreds of vertical AI startups — legal AI, healthcare AI, accounting AI.
The thesis for these companies is that sector-specific regulation, distribution, and data taxonomies create a unique set of requirements. And so generalist platforms can’t compete.
You’ve made the opposite bet. That the underlying tasks AI performs – parsing, research, writing – are fundamentally content-agnostic. And that well-coordinated agents, specialized for these different subtasks, can handle most enterprise workflows, regardless of sector.
Why do you think horizontal AI represents a more durable product strategy?
Before transformers5, the industry assumption was that AI had to be very specific. In early image detection, for example, we had different models for identifying cats versus dogs.
But as we built and scaled LLMs, it turns out that training on a variety of information makes general reasoning more robust.
It’s like the human brain. If my kid only studies math and never learns language or music, they won’t actually be better at math.
Diversity of input strengthens the underlying reasoning capability.
That same principle applies to AI systems. The core operations – parsing, research, synthesis, execution – are the same across domains. Sure, we need to do some extra work to train on the specific vocabulary of HR or finance. But fundamentally, the tasks are the same.
A horizontal platform sharpens that reasoning across every domain it serves. A vertical company only learns from one. That’s why, maybe counterintuitively, a horizontal platform actually lets us build vertical-specific AI products better and faster.
I also think a lot of AI startups copied the SaaS playbook as the default without interrogating how the underlying product economics have shifted.
That’s right. In traditional SaaS, every workflow and integration has to be explicitly coded. Expanding scope means increasing your engineering spend.
So vendors specialized. They built separate apps for different sectors and corporate functions, each with its own data model, team, and sales motion. Over time, those applications got bolted together. They turned into monster apps like ServiceNow, with endless configuration knobs and months-long setup.
Then AI came along. The first instinct was to apply these new AI capabilities to the same specialized workflows. So we get legal AI, healthcare AI, finance AI. But that specialization only exists in the first place because customized SaaS tools were usually too expensive to build and maintain.
AI doesn’t have those constraints. So we don’t have to build products for these silos any longer.
AI seems to challenge the assumption that sector is the right organizing principle for software.
The way I think about it for an enterprise buyer – they just want simplification.
We’ve over-rotated on specialized software. Right now, one organization might have five apps that do roughly the same thing. And now we’re bolting hundreds of agents on top of those five different systems. That’s a lot of unnecessary complexity.
I spent 15 years at Google. There was a time when people thought separate, vertical search engines would win. We talked about it a lot internally. Turns out, people just want one place to go.
It’s the same for enterprises. Complexity is killing the enterprise.
So if simplification is what enterprises are principally buying with AI, that raises a product question – simplify what?
And what I’m hearing you say is that AI-native companies need to conceptualize work at the goal level, not the task level. Start with the outcome, not the existing tooling.
If you’re solving for performance management, the question isn’t, “how do we automate data collection for our HRIS?” It’s – “what do our employees need to improve?” The former automates semi-annual reviews. The other gets you real-time feedback as people work.
Goal-level framing doesn’t fit inside one software category. “What do our employees need to improve?” pulls from HR, IT, finance – all at once. That’s what pulls you toward a horizontal product.
And it also simplifies things for the customer. You end up with one system organized around the employee, not five organized around departments.
Exactly. And right now, there’s a leapfrog happening. Large enterprises can go from very old legacy software to an agentic solution, and skip over using the modern cloud tools with prescriptive workflows.
05 | The great displacement?
Worker displacement is an important topic right now.
Optimists point to prior technology cycles. There will be some displacement, but on net AI will take away tedious work and create new types of jobs.
Doomers say this time is different. That the speed and breadth of AI will break the historical pattern and cause mass displacement.
You see firsthand how enterprises are deploying AI, and how humans interface with the technology every day. Where do you come down?
Right now, large enterprises are not radically displacing people.
Most employees are overworked. Think about a nurse at a hospital, or an HR team buried in tickets. In my experience, AI is mostly freeing them from administrative tasks – clearing a backlog of work, and making employees more productive as a result.
In the near term, I think that trend will continue. And as a result, people will shift more of their time to core, higher-value tasks.
Ten years out, major re-skilling is probably needed. And within that time frame, some will feel the impact faster than others. Customer support reps and software engineers, for example.
But even those roles won’t just disappear. They will look different. Workers will have to reconfigure their jobs around AI.
Software engineers, for example, will have to learn to work with agents to build software, rather than actually writing software themselves. They’ll still be responsible for building and maintaining systems, even if they are not primarily doing the coding.
I’m mostly going off intuition, but I think there’s a lot of latent demand in the economy right now. Backlogs everywhere. Employees are overloaded. Managers are getting increasingly overwhelmed, which leads to short-term thinking and risk-aversion.
If AI clears some of that backlog and lets teams get to the work they’ve been deferring, the floor rises for everyone. With less overhead, small businesses can now compete with larger companies. The economy expands around a new baseline.
I think you will see a lot more companies in the economy, but they will run leaner.
06 | Your code is my opportunity
You have a unique seat. You’re deep in the cutting edge of AI capabilities. You also serve legacy companies and see how this tech gets adopted in practice.
How does that inform your own angel investing? Where do you see durable product value in AI?
I think quantum computing and AI together will open up interesting opportunities.
Also, with so many agents everywhere, agentic security is an area of interest. I like talking to companies tackling governance and safety.
At the product level, I have a simple framework – is it solving real problems, and can it work at scale? There’s so much hype in AI. I need to see that the product works in production.
Also, speed and execution were always important in startups. But the time window is getting dramatically compressed.
We were at an HR conference recently. One of the other exhibitors, a legacy company, was describing their product. One of our solution architects was listening, and built a working version of their entire product. In 15 minutes, on top of Ema.
Trust, security, enterprise viability are going to matter a lot in a world where you can vibe code anything in 15 minutes.
Jeff Bezos famously said, “Your margin is my opportunity.” Well, now your code and people are my opportunity. The more code or bureaucracy you have, the slower you are going to be.
I think many of the fundamentals still hold. Network effects, unique data – those still matter. Even if AI means you’re building those into the product in new and different ways.
For us, we get more defensible the more we learn about our customers. Once we have a good context graph and procedural knowledge, the next deployments become easier and easier.
That’s also part of why we went horizontal. If our compounding asset is knowledge of the customer, then it gets easy to build different agentic systems on top of that, across different functions.
Great stuff, a lot to think about. Thanks for doing this, Surojit.
Thanks for having me.
In computer science, a deterministic system always produces the same output given the same input. A non-deterministic system can produce different outputs for the same input, depending on how it reasons through the problem.
Model convergence is the hypothesis that frontier LLMs – OpenAI's GPT series, Anthropic's Claude, Google's Gemini – are trending toward similar capability levels over time. The underlying mechanism is explained by scaling laws. Performance is primarily a function of compute, data, and architecture. Because all major labs use transformer-based architectures, train on largely overlapping internet-scale data, and operate at comparable compute budgets, they tend to land on similar performance curves.
HLE (Humanity’s Last Exam) is a benchmark of 2,500 expert-level academic questions across 100+ subjects. Designed to test the limits of frontier models on problems requiring genuine reasoning, it remains one of the few major benchmarks where top models still score below 40%.
OCR (optical character recognition) is a specialized AI model designed to extract text from images, scanned documents, and PDFs. Unlike general-purpose LLMs, OCR models are optimized for parsing visual layouts — tables, handwriting, low-quality scans — where a frontier language model would be overkill or fail at scale.
The transformer is the architecture that underpins virtually all modern large language models. Its key innovation, the self-attention mechanism, allowed models to process entire sequences of text in parallel rather than word by word, dramatically improving both training efficiency and output quality.