

We are entering the era of the infinite codebase.
With agents, the code repository is no longer a fixed artifact maintained by hand. It’s becoming a living system, where code is constantly being generated, forked, and rewritten on demand.
The data reflects this. In just a few years, the volume of code and software projects flowing through GitHub has grown exponentially.
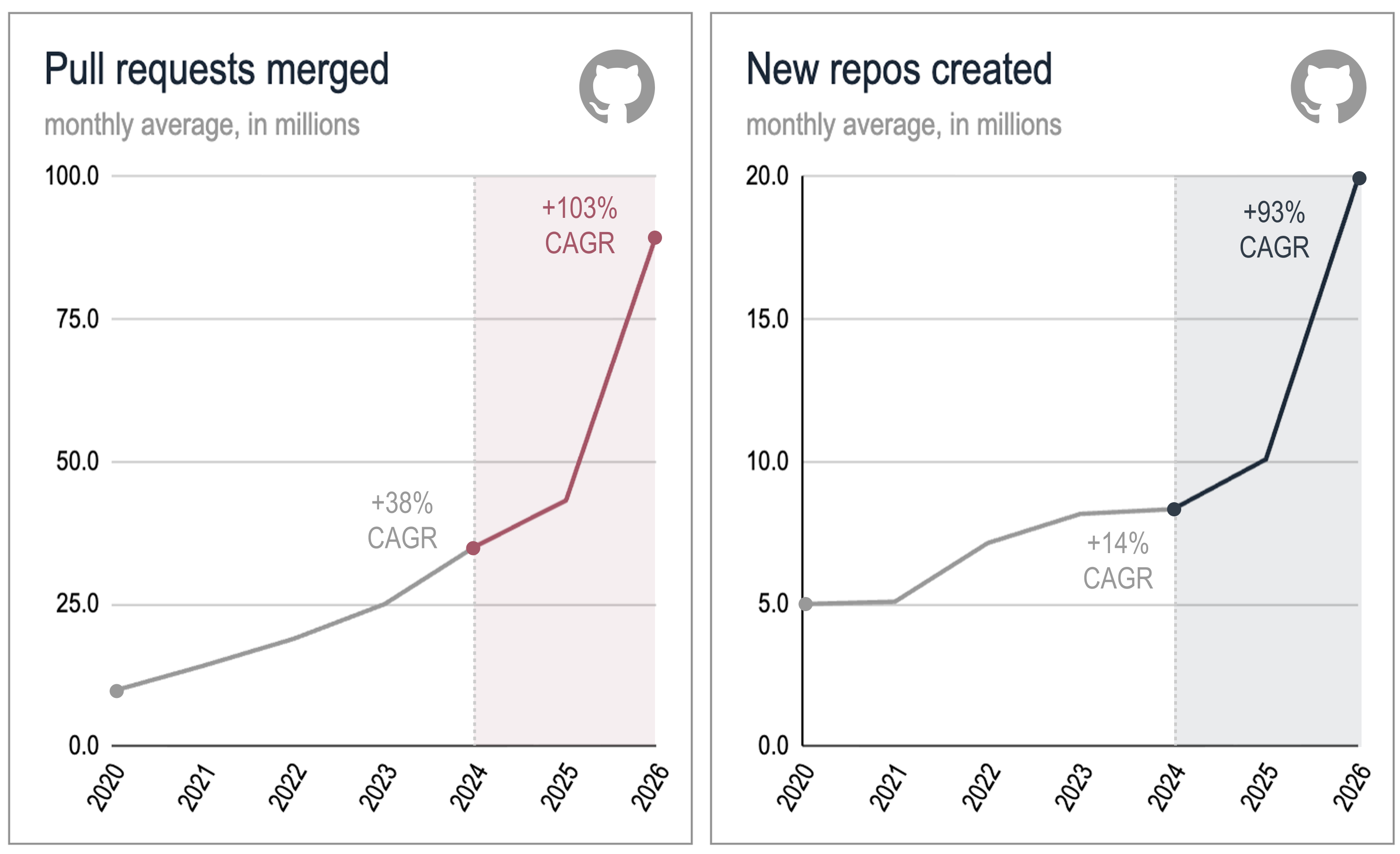
Sources: An update on GitHub availability (2026); GitHub Octoverse reports, 2020–2025.
All this code has strained developer workflows, creating a crisis of legibility.
When an agent produces thousands of lines in seconds, it creates a black box. Developers inherit mountains of “ghost code” they can’t fully explain, maintain, or debug. The problem balloons as teams of humans and agents, each with different working styles and objectives, pile changes into the same project.
Existing dev tools weren’t designed for this level of throughput.
Historically, Git, the standard for storing and versioning code, captured what was written – the the code itself, tracking diffs between contributors. But it did not capture why – the spec and prompts that initiated the work, the paths accepted and discarded by the developer and agents, the trail of decisions that collectively tell the story of how a piece of software got built.
Now that code itself is cheap and abundant, the why – the full reasoning process behind the code – is a more valuable data asset than code itself.
With it, agents can stop repeating mistakes and deliver higher accuracy, which saves time and token spend. Humans can more easily audit what was written and why. Handoffs between agent and human collaborators are more seamless.
This insight led former GitHub CEO Thomas Dohmke to launch Entire, a new development platform and system of record for software in the era of agents.
Entire’s CLI1 hooks into agent workflows and captures the full coding session – all the developer prompts, agent transcripts, and tool calls. It then indexes and versions that data into a searchable, legible record that sits alongside the code. Every commit now traces back to the exact conversation, the entire history, that created it for humans and agents to read.
It’s one of the AI-native products I’m most excited about right now. It’s seamless and easy to use – a beautiful blueprint for how humans and AI will collaborate at scale, letting us work at a higher level of abstraction without losing control.
I sat down with Thomas to talk about how software development is changing, his strategy to own the agentic record, and what happens once we open the black box… when we capture the soul of software.
01 | “My name is Thomas, and I’m a developer.”
EO: Thank you for doing this, Thomas. I’d love for you to tell the folks about you and what you’ve done.
TD: My favorite line for the past few years has been, “I’m Thomas and I’m a developer.” I used to be known as the CEO of GitHub, from 2021 to 2025. I’m not the founder of GitHub. Chris, Tom, and PJ are the founders, but I became the CEO after Nat Friedman decided to do other things.
I’ve been doing software development since the early ‘90s. I started on a Commodore 64 and an East German Robotron computer. I’ve been passionate about software development throughout my career.
How’d you get to be CEO of GitHub? What was that journey?
I had a startup in Germany called HockeyApp.
It was a mobile app development platform, distributing your beta builds to testers, collecting crash reports, feedback, analytics, those kind of things. In late 2014, Microsoft acquired our company. As part of that, I moved over to Seattle to start working in Microsoft’s developer division.
In 2018, Nat Friedman, who at the time was one of the CVPs in the developer division, pitched to the Microsoft Board and Satya to acquire GitHub. He pulled me into the deal, as he needed the “stern German” to execute the deal behind the scenes and decide what integration model GitHub should have within Microsoft.
As the deal closed in October, I joined GitHub together with Nat as VP of Special Projects. Then in 2021, Nat decided to do something else, and Microsoft’s leadership team promoted me into the CEO position.
02 | We’ve reached the highest level of programming
You’ve been a software developer for a very long time. Software development is undergoing one of the biggest shifts that it’s ever gone through.
Code used to be written primarily by humans. We’re now at this moment where it’s written predominantly by machines. At a macro level, I’d love your thesis of how software development is going to change going forward.
If you actually zoom out over the past 50 years, you realize we have always gone through these kind of transformations.
We first went from these punch cards, to assembly language, to the first proper programming languages like BASIC.
And then actually the biggest shift I’d say of the ‘90s and early 2000s was open-source. All of a sudden you had access to all this free, publicly available software. You could see the source code – but more so, you had access to a worldwide community that you could chat with. Before, you had AOL or CompuServe or whatever at home, and you had to figure it out all by yourself.
So open-source opened the Internet, opened the world, to software developers.
And now with AI, we have the next big shift.
And all these shifts move us up the abstraction ladder. COBOL and BASIC and assembly language, that was really low... you had to understand how much memory is, and caches, and what the PCI bus is,2 and all these kind of things to make a performant app. And with AI now, we have reached the highest level, in the sense of our thoughts are all in human language.
And so how tangibly does that change the way developers work?
Project planning and project execution in software companies starts with an idea, often written in a Google Doc or in a tracking system like Jira or Linear. Then it is manually converted from that big idea into smaller building blocks until you’re ready to hand it off to a developer to write the code.
Now, you can actually with AI just go from idea to a prototype with a single written prompt.
Depending on how specific you were with your original request, and how much code already exists, the AI might even suggest a programming language, frameworks, and those kind of things for you.
And so I think that’s the first shift, is you have somebody to plan with that gives you all kinds of ideas. I think we underestimate the power of just that, because it unlocks the creativity itself.
It gets to the point when you want to implement that plan, and you tell the agent - “Here, make it so.” And then, it comes back to you and it asks questions as it gets stuck. That feels very magical – you’re using natural language, and it builds you, more or less, all the code.
And so all these things that have taken so much time, that got me out of my flow, got me out of my stream of thoughts on the big idea that I’m having, I can now hand off to an agent.
For example, on Saturday I was working on some hobby projects. I had a movie on my laptop screen. And on the big screen I had my terminal windows.
It was coding in the background…
Yeah, I was typing prompts into these different windows, and it felt like, “Holy shit, I’m living in the future.”
03 | Encoding a thought process
Let’s double-click into the storage layer, which is where Git sits.
Git launched in 2005. And it’s been the standard for version control and code storage.
I think part of your thesis is that in the age of agent-generated code, Git is insufficient for the developer workflow. So I’d love if you could give a sense of – what does Git do, why is it insufficient, and what else needs to be captured in order to unlock real value?
It is not insufficient as a technology. Because ultimately, it doesn’t matter to Git whether you’re storing code files or text files.3
You’re right. 2005, it had 20 years anniversary last year. And in the grand, general scheme, Git is the version control system that will be around – making a bold prediction – in 20 years and more.
Now Git, by design, stores your code files or any text files in your repository. And the other storage mechanism is the commit message.
What’s missing though, what you could never get in a world before agents, was the thought process of the developer… Where did I start my day? What decisions did I make? Where did I course correct because I saw unit tests are failing?
So that session log is becoming a more and more important artifact. And our hypothesis is that you should store that always together with the code, so you have both of them together.
And the immediate benefit of that is that all my co-workers can read this thought process. And you can run another code review agent on top of this transcript to say, “What are the decisions that Thomas made?” So you don’t have to read through every tool call and every reasoning step of the model.
Imagine you join a company like Shopify today. The company is over 10 years old, has over 4,000 engineers. Imagine how much code they’re producing every single day, every single week. Over the lifespan of 10+ years, if they would’ve logged all the sessions, the institutional knowledge that tracks over time – and that is accessible to me or an agent – is going to be incredibly valuable. I can figure whether the code was intentional or whether an actual test failure was a mistake.
So there’s this meaning layer, which sits on top of the actual code, that Entire is capturing. Talk to me about how you capture that, what that primitive looks like.
The first product that we launched earlier this year is the Entire CLI. You can easily install it with one command. It lets you pick the agent you’re using (we’re supporting more or less all the major agents). And that’s it.
It sets a hook4 for that agent that’s transparent to you. And now you can use your agent as you did before. And every time in the agent you type “commit/push,” it not only pushes your source code, it also pushes your session log into the same repository. And we run a post-processing step on it, to remove secrets and other personal information.
It’s really simple. You install it once. It captures all your session. And it stores that session in the same Git repository as your code.
And then we have certain features on top of it. For example, you can write what we call a Dispatch, like a summary of all the changes in that repository. Or you can code review, what we call Entire Review, all the changes in your branch before you submit the pull request.
What is that unlocking that otherwise was not possible?
The biggest unlock here is that it just works in the background. Of course, you can go into your .codex folder and find the JSON file of the session log, or extract it from the SQLite database that some agents are using. But with Entire, it’s just seamless for the developer. You don’t have to do any manual steps. Every time you push, it just pushes all your session logs.
So I think that’s the primary unlock.
And then, obviously, we enable you to do a lot of things with these session logs. I already mentioned Dispatch and Review. A very simple scenario is… lots of developers now have a second or third Mac at home. What you can do with Entire, because it tracks your session in the repo, is you can actually resume a session on a different machine.
It really is about improving the convenience for the developer when working with these agents. And because it’s in the Git repository, it stores all the sessions of all your team members. And so you have a shared knowledge base to work from. Not only the codebase, but all the intent, or the semantic information, stored in the repository across all your team members.
04 | Formula 1 as startup strategy
One of the things I love is that you build in public. And the velocity is pretty impressive.
You’ve established Checkpoints, which is the data primitive. You’ve made it user friendly. You’ve added collaboration. There’s now this web app that allows for a lot of clarity and a good UI to help explore what’s happening around the codebase.
But I’d love if you could talk about the product roadmap.
We have a stated vision on our homepage. And we are working in three layers.
We already talked about Checkpoints and Sessions. That’s what we call the semantic layer. That’s the middle layer in our stack.
On top of that is the user interface. We actually treat the CLI and the web viewer as equal surface areas. One of our first principles is everything has to be CLI-first, as that’s where developers are actually spending their day.
If we think about GitHub from a user base perspective, the primary primitive is the repository. And the repository is effectively a file browser – it shows your folders, your files, and the content of those files. That’s the user interface in GitHub today. We think that’s not something that will work in this age of agents, where I often don’t look at the code at all anymore. And so we think the pull request and the repository have to change in the user interface layer.
And then at the bottom is the question about how do you store all of this? And Git is our answer. But we believe you have to transform Git into what it actually was intended to be, which is a network of more than one host. Not storing it all in a centralized place, but having it in as many places as possible – to have not only high availability, but also let agents query these repositories at very high rate limits.5
How do you think about Entire’s surface area relative to a few different players. So you have GitHub, you have the coding agents like Cursor or Claude Code...
One of the things I’ve seen is a lot of these AI-native products have a lot of blurriness around where the edge is.
How do you think about that for Entire? What is your domain that no one else can touch? Or won’t touch as well as you’re working with it?
I think that’s fundamentally a perspective of investors, that they love to see companies that nobody else can touch. But everything in software can be cloned. And, in fact, can be cloned now much faster with agents.
I like to think about business like sports leagues.
Formula 1 is one of the most competitive sports out there. There’s a new world champion every year. And maybe multiple years in a row it’s the same one, like Lewis Hamilton or Max Verstappen. But there’s always the chance that some other team can both win a race, or can win the season.
So we should realize that in this world where now agents write more code, the competitive advantage is not that you have a space carved out for you that nobody... In fact, I would be suspicious if no competitor would be trying the same thing, because it means you’re probably on the wrong path.
But it’s also things like our brand. The GitHub brand is famously super loved by software developers. We want to establish a brand like that in the developer space. I think that is equally important as building a great product.
You can’t have a great brand and a shitty product, because developers will figure that out really fast. But also, you can have the greatest product in the world, but if you suck at marketing and branding you won’t win.
And look, at the end of the day, any company is defined by the team.
This brings us back to Formula 1. The team is comprised of the people – the drivers at the command stand, the race engineers, and all the people in simulation developing the car. And you can’t become the driver’s champion without having a great team that builds you a great car and has the right strategy.
The same is true for companies and for startups. They have to build a great team, one that is highly competitive, one that wants to win.
So product, brand marketing, and team. Those are the crucial ingredients for us to compete in the market regardless of whether any of our competitors is building the same thing as us.
Or vice versa, right? Like, you could also ask the question, what’s stopping us from building another IDE or another coding agent?
OK, but you were the CEO of GitHub. So you know… they have massive distribution. They have a clear head start in terms of developer love and mind share.
So what’s your strategy to become the source of truth for the agentic record, to beat someone like GitHub to it, to get the product to that level?
In the short term, I don’t have to get to that level. GitHub’s goals are very different than the goals that we have, and that obviously is true for many incumbents and disruptors.
GitHub is a great platform and is a great team. They’re highly focused on their own goals.
Rumor recently had it that they passed $3 billion in annual revenue run-rate. Let’s say they need to grow by 40%. That means they have to find $1.2 billion in additional revenue next year. I don’t have to find a billion in revenue next year. I’m at a very different stage in my company’s life cycle.
The game the disruptor is playing is finding a very small slice of the market and trying to disrupt it. And today, we are in the space of tracking all these sessions and doing cool stuff with the data we are collecting there.
We are effectively becoming a system of record for agentic work. And that means we are recording these agent sessions, and then we will have agents reason over those recordings. And we’ll use that to improve the developer workflow.
So I think one of the theories behind Entire is that as agents get better, this semantic layer, this layer of meaning, becomes more valuable. Why do you think that’s true?
For example, when we have GPT-8, why does this semantic layer still have value? Versus the models and agents being able to stare just at the codebase and reason over that, and that’s enough?
Because the codebase doesn’t codify all the decisions that you’re making as a developer.
Take a very basic example. If your code is written in Go, how would the agent know why you picked Go as a programming language and not Rust, or Python, or any of the other modern programming languages? Why did you structure the codebase that way?
There are hundreds, if not hundreds of thousands of decisions, that are flowing into a software project that decide about scale, functionality, performance, security, compliance, those kind of things.
Those decisions have very major implications for your business. Those are all decisions that can be very different between two projects that otherwise do the same thing.
So what’s an example of that? What does that institutional knowledge unlock that smarter or better agents can’t deliver on their own?
I think Jensen, the CEO of NVIDIA, recently talked in a podcast about how their forward deployed engineers are helping the big AI research labs to optimize their stack for each model individually. They can find performance optimization in factor of 2x or 3x – just by NVIDIA engineers looking at the CUDA6 stack and optimizing it for a specific model.
If an agent would be able to just do that, we wouldn’t need to send out all these forward deployed engineers. But the agent can’t today, because it doesn’t have the decision log, and also the years of learnings from the engineers.
Now, does that mean that models can’t get better analyzing this code? Of course they will. But the humans instructing the models are also getting better.
Peter Steinberger of OpenClaw fame comes to mind. Read his blog – he has been tinkering with these agents for like a year. As he got more proficient with these agents, he realized what the needs are that he has, and what the technology can solve for him.
That’s where we are in this journey. And that’s why I think bringing those learnings, the institutional knowledge of the project and the company at the context layer into the repository, is incredibly important.
That’s actually really interesting. By creating this context layer you’re actually changing the way the developer works, and then that has this circular feedback loop.
Suddenly, developers have this rich data set around intent that they can query and build from. And then that becomes this fundamentally new starting point for their work. And that incentivizes more and more engagement over time... That’s really interesting.
Yeah. Our company was founded in September. I think we set up the Slack in August. Everything, every discussion that we had since then, is codified in that. And of course, that’s one context layer. For many startups, Google Docs is another such context layer. Bringing these all together will be incredibly important.
And I think in-person companies will have to ask themselves the question, how do I record all my meetings and hallway conversations and what have you? Because otherwise I’m losing like 20% or 30% of my company’s knowledge.
The upside of in-person work – being able to brainstorm on a whiteboard – is now becoming a disadvantage compared to remote-first companies who have their “whiteboards” and discussions online, which is easier to track.
Right. There has to be an ingestion mechanism for all of this context that we’re now generating.
Except it becomes socially awkward. Last time you and I met, we were in a coffee shop. I don’t know if you would have appreciated it if I had recorded the whole conversation. You’re not saying certain things when you know you’re always on the record.
05 | Reaching a new class of builder
I want to talk about distribution in the age of AI.
It’s getting very noisy. There are so many products out there. What are some of your learnings, especially from GitHub, about how you both reach developers, and also maintain developer love?
Most developers have a really low threshold for what they’re tolerating in their workflow. And so, you have a very short amount of time to delight them, to show them that there’s value. Otherwise, it’s uninstall.
And then, if you fuck that up, when do you have another chance with that same developer? It’s certainly not three minutes later.
So the first experience with a product... Installing, in our case, the CLI... Working with your agent and seeing the first commit going through... If that’s not a great experience, a delightful experience, you’re immediately reducing your chances of long-term wins.
I also fundamentally believe developer tools are only successful if they go developer-first. Not decision-maker first. Not CTO-first.
Now, in the last year or so, you actually see, more and more C-suite CEOs, CTOs, CIOs, CISOs even, realizing that these agents get them back into coding. You actually now can be a developer and an executive at a big company again. Now, even going after those executives is still developer-first, right? Because you’re reaching those people in the minimum amount of time that they actually have available for coding tasks.
I don’t think as a developer tool you have a chance to get high distribution by going enterprise-first. Often, design partners have all good intentions, but they’re actually pushing you in the wrong direction. Because they’re serving the need of the large organization, not the need of the best developers in your organization.
The really cool thing about a software development company that builds tools for developers is that we are our first customer. The other principle that we have, I already mentioned we are CLI-first... The next one is we’re building Entire on Entire. I think that is equally crucial.
Like, if we are not using our own tools, our own processes, our own implementation of the ideas we are having, we shouldn’t go out and try to sell that, or launch it, to other developers.
And I think that is what ultimately becomes a competitive advantage over much larger organizations that have to serve the needs of really large deals.
So you hit on something that I wanted to touch on, which is the changing face of the developer.
As coding becomes much more accessible to non-technical folks like product managers or designers, how do you think about reaching them, this new class of builder?
We have three hypotheses around this.
First, we believe the roles in a company are collapsing. You will have a Venn diagram where what the product manager is doing, a designer is doing, a marketer is doing, and an engineer is doing, all meets in the center – at code.
The designer is transforming into a design engineer. The product manager should move away from just writing specs and creating mock-ups in PowerPoint to creating a prototype for every feature that you have in mind. And your code artifact – together with the intent, the session log – becomes the artifact that you’re handing over to the engineer.
So as a product manager, instead of filing a ticket in Jira, you’re basically opening a draft pull request that has your session log, which we are capturing with Entire, and some draft code.
And maybe the engineer looks at this and says, “This is terrible code.”
But as they also have the session log, they can then tell the agent, “Well, refactor this branch to align with how we would do that.” They can leverage the session log, the Checkpoints, all that semantic information to do that in such a way that what the product manager intended is still being implemented.
That goes to the second hypothesis, which is the context is collapsing. You need all that information in a single “cloud,” in a single space. Whatever the agent needs to make the decision and implement the feature needs to be accessible in a single, unified context layer.
And then the workflow is also collapsing… Like, are we still going to file a ticket in Linear that somebody else has to pick it up? Or can we just feed that “ticket” directly into an agent to shorten the planning and tracking workflow?
And so we think the workflow will ultimately collapse in much fewer steps. That allows a single builder in a small and large company to bring a feature all the way from idea, through conception, design, prototyping, implementation, testing, into production.
Well, thank you so much for coming in and spending the time. I am a big fan of the product, and I hope this gets out to lots of developers out there.
Thank you so much for having me.
A command line interface (CLI) is a way of interacting with a program by typing text commands into a terminal rather than clicking through a graphical interface.
Memory is the fast, temporary storage that holds data and programs while they're running. Caches are smaller, even faster stores that sit between the processor and main memory, keeping frequently-used data close so the processor isn’t left waiting. The PCI bus is the physical pathway that connects components like graphics cards and network adapters to the rest of the machine.
Programming used to require knowing how these pieces behaved and budgeting for their limits. Higher-level languages and abstractions have since hidden most of it from view.
Git is a content-agnostic framework. It tracks and versions files without regard to their content. Code, prose, and data are treated similarly. Thomas’ claim is that Git will remain relevant, in part because content-neutrality is part of its design.
A hook is code that runs automatically when a specific event occurs, rather than when you call it yourself. It “hooks into” an existing process so that some action – logging, capturing data, triggering a check – happens every time that process runs, without anyone invoking it directly.
Git is distributed by design – every clone is a complete copy of the repository, and so the same history can live on many hosts at once rather than on one central server. Platforms like GitHub re-centralized it in practice, routing everyone through a single host. Thomas is describing a return to Git's original form – replicating repositories across many hosts so no single server is the bottleneck
This matters for repos being read by agents, which query far more frequently and aggressively than humans. Point all agent traffic at one host and it hits rate limits fast. But spreading agent queries across many hosts in parallel gives agents more reliable access and the ability to work at scale.
CUDA is NVIDIA’s software platform for running general-purpose computation on its GPUs. A GPU has thousands of cores that work in parallel, and CUDA is the layer of languages, libraries, and tools that lets developers program them. It's the foundation most AI models are trained and run on.
