
The Dark Matter of Work

This post maps out a new class of AI products that observe how people and agents work, and then encode what they learn as a new data layer. These products are built to get stronger and more defensible as models improve.
01 | The dark matter of work
Right now is a difficult time to build and invest in new technology. Model capabilities are improving so fast that many AI-native products, even those with real utility and traction, are quickly becoming obsolete.
In my own diligence, I’ve had to think very, very hard about this question…
If models get 50x better, why does this product still have a right to exist?
To reason through that, I start with what models are fundamentally good at.
Today’s models transform unstructured inputs into outputs. They do three things extraordinarily well: (i) understand and generate language, code, and images; (ii) reason through multi-step problems; and (iii) execute commands within software systems. They’re getting better at these tasks every day.
If your product’s value prop hinges exclusively on enhancing the AI along these dimensions – smarter reasoning, better retrieval and context management, deeper domain expertise – you’re one model release from obsolescence.
Durable product value has to come from somewhere else. Not from patching short-term gaps in intelligence capabilities, but by creating entirely new inputs for the AI to work with.
Put differently, the best product strategy isn’t about making AI smarter – it’s about expanding what the AI can see. After all, any model, no matter how powerful, can only reason over what it observes.
This turns out to be an old concept.
In 1991, Ikujiro Nonaka published one of the most cited management papers in history – The Knowledge-Creating Company. His thesis is that organizations run on two kinds of knowledge.
Explicit knowledge is easily codified – a process, a policy document, a decision tree. Tacit knowledge is craft. It lives in human intuition, practice, and judgment. It’s the customer success manager who knows which clients need a preemptive call. Or the engineer who senses which parts of the codebase are fragile before the logs pick it up in production.
Tacit knowledge is the “dark matter” of work – the invisible reasoning, intent, and institutional memory that connects raw information to action. It doesn’t live in any system of record. It expresses itself ephemerally, through human behavior, in the course of day-to-day work.
That is, until now.
A new class of AI products is starting to capture this invisible layer – not by asking people to document what they know, but by directly observing how they work…
…vision models that perceive user activity inside applications across thousands of daily sessions…
…language models that extract reasoning from employee conversations scattered across Slack and email…
…code provenance tools that trace every AI-generated function back to the prompt, the agent’s chain of thought, and developer corrections.
These products aren’t bolting AI over a preexisting database. They’re producing a fundamentally new kind of data asset – a dynamic, contextual layer that never existed before.
02 | Making the invisible visible
What does this look like in practice? The strongest products in this category share four properties.
1/ They generate a fundamentally new kind of data asset. One that has never appeared in any system of record.
2/ They don’t just capture what happened – they encode why. Raw behavioral data gets translated into a representation of meaning, one machines can read and act on.
3/ Their observation is continuous and self-reinforcing. The system quietly observes how people work, distills patterns, and feeds that back into the product to improve accuracy and automation. This in turn drives more usage, and therefore generates more data to learn from.
4/ They create a data primitive that others build on. Structured context that third-party agents and products have an incentive to integrate with and consume.
A couple early products are already building in this direction:
EXAMPLE #1: DEV TOOLING // ENTIRE.IO
Entire is building a new storage and provenance layer for code.
The founding team came from GitHub and saw firsthand the limitations of git1 in the AI era. Specifically, git stores code as text files and tracks version history, but has no mechanism to capture what the code means or why it was written.
That was fine when humans wrote every line and held the design in their heads. It breaks when code production is outsourced to AI agents.
Entire solves this by making this invisible layer – the history and meaning of the code – explicit.
Their first product, Checkpoints, automatically captures the full agent coding session from the IDE2 — all prompts, agent output and reasoning, and developer corrections. When the developer commits3 to the repository, that context is permanently linked to the code as a structured, queryable asset, available to every future agent and engineer who works on the project.
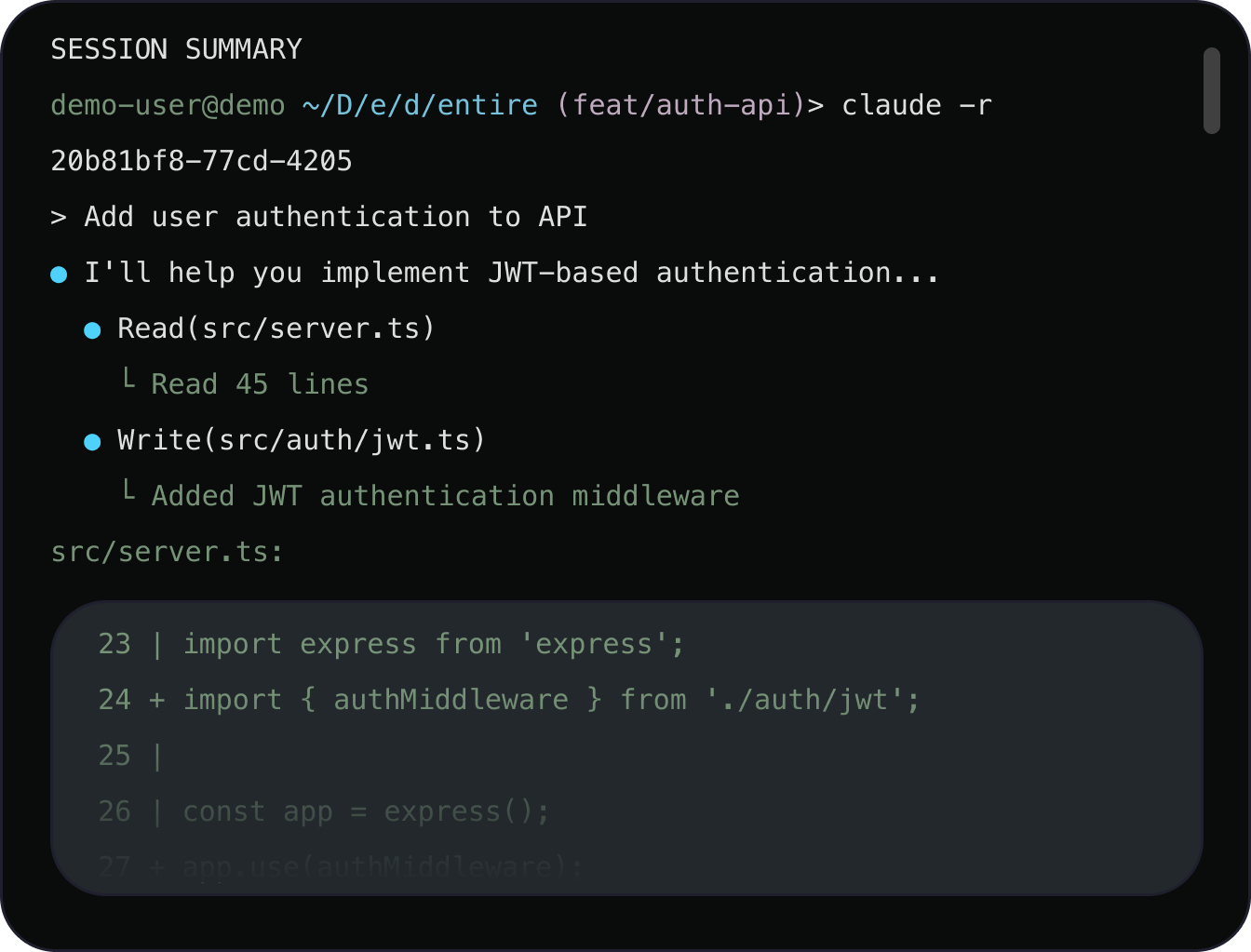
Sample session summary for a single commit, showing the developer’s original prompt, the agent’s tool calls and reasoning, and the resulting code changes. [source]
Here, every coding session contributes to the system’s understanding of the code, its interdependencies, and how it came to be. Over time, this turns the code repo from a static storage archive into a living record, one that gets more robust with every commit.
And better models only amplify that advantage, because as smarter agents come to market, they can extract more and new types of value from the full context and history.
EXAMPLE #2: HORIZONTAL SOFTWARE // WORKTRACE.AI
Worktrace is building a next-generation RPA4 product. The founder came from OpenAI and saw that the biggest bottleneck to enterprise AI adoption isn’t the technology – it’s knowing what workflows to automate, and how to do so.
Today, figuring out what to automate is manual and slow – teams either map processes by hand or rely on software tools in UiPath or Zapier that capture surface-level behavior like clicks and data flows.
Worktrace replaces that.
The product integrates with existing tools like Slack and Linear, quietly observing how employees work. But it goes beyond surface-level process mapping – it parses intent, capturing why employees take certain actions and how they complete the same task in different ways. Why does a coordinator skip certain steps under time pressure? Why do two people follow different paths to the same outcome?
The output is a prioritized map of automation opportunities, ranked by potential impact, with a spec that outlines the right AI model and agent design for each task.
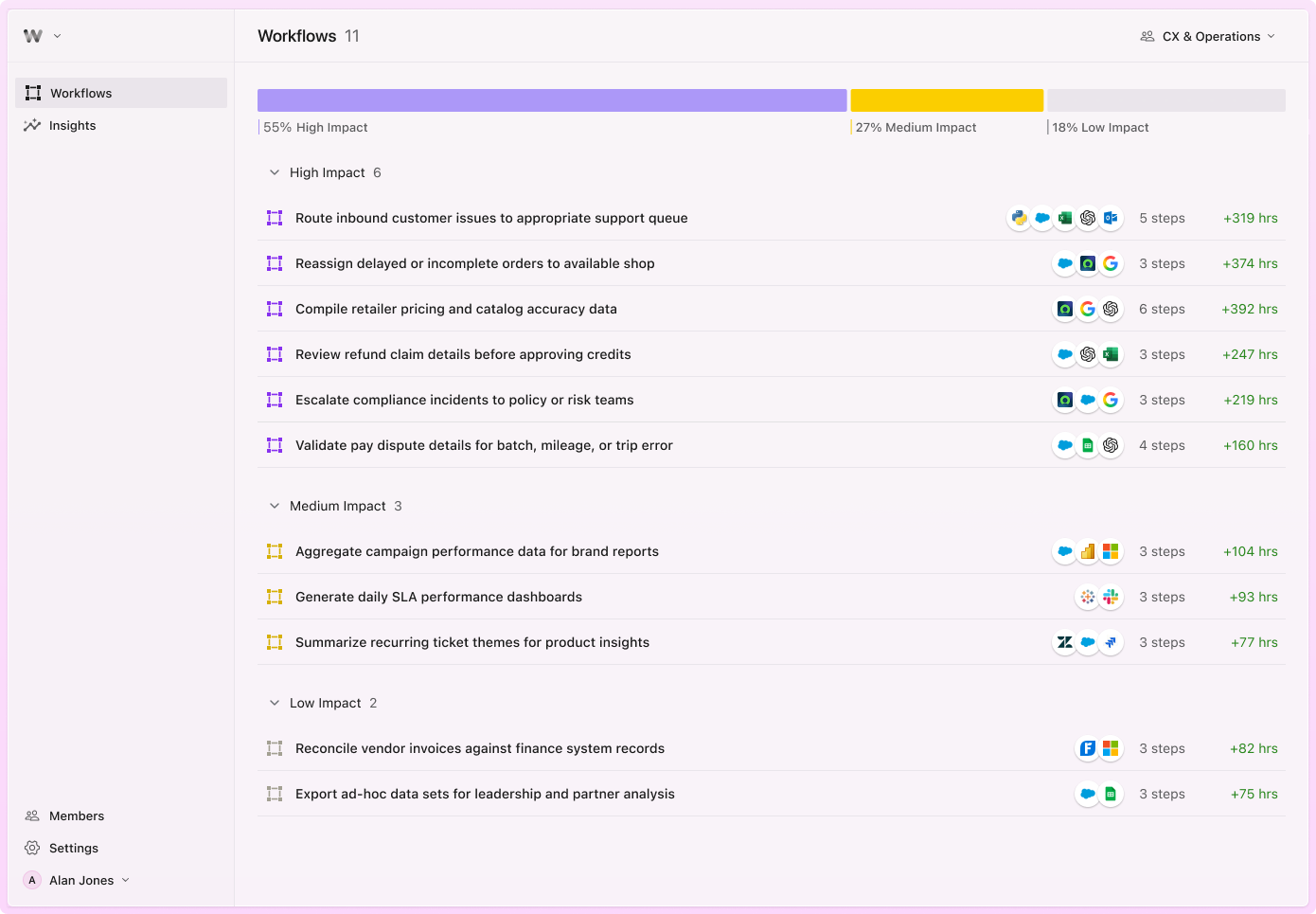
Sample discovery dashboard, ranked by automation impact (hours saved), with the applications involved and number of steps for each. [source]
Rather than competing on “better automation,” Worktrace owns something far harder to replicate – a nuanced and dynamic understanding of how employees actually work and where AI can have the most impact.
As models improve, two things happen: (1) the live observation captures richer, more complex workflow patterns, and (2) Worktrace can revisit its accumulated history to surface automations that earlier models couldn’t detect.
In other words, the product only gets more valuable as AI accelerates.
03 | The anatomy of a durable product
There are a number of other products – across productivity, vertical SaaS, and developer tools – developing a similar architecture. Each looks different on the surface. But underneath, they share the same product template.
Step 1: A perception mechanism
These products need a way to observe activity and behavior that was previously invisible to software, by watching activity inside and across applications.
This capability is distinct from a knowledge or context graph, which organizes relationships between data artifacts that existing systems already produce. For example, a knowledge graph might map the relationship between a support ticket, the customer's account history, and the agent who escalated it. But all of that data already lives in a database somewhere. An observation model, on the other hand, captures what doesn't – the Slack side-channel that explains why the ticket was escalated in the first place.
A few tailwinds are making this observation capability viable and more efficient.
Techniques like distillation5 and quantization6 now allow small, purpose-built models to run locally on phones and laptops, enabling simple tasks in the observation flow like data capture and entity extraction to happen at the edge. This can deliver a cheaper and more secure architecture, since raw data doesn’t need to leave the device.
Additionally, multimodal models can now process vision, audio, and text simultaneously, rather than requiring separate models for each. As multimodal capabilities improve, this dramatically expands the range of behavior that software can perceive and analyze.
Step 2: Converting raw inputs into meaning
Most of the product value – the “secret sauce” – lives in how these systems convert perceptions (from Step 1) into structured, semantic data.
The exact tactics and implementation varies, depending on the product and category. But there are a few things to look for when evaluating whether a product is doing this well:
Is the output schematized into defined entities, fields, and relationships? Is it something a machine can read?
Is the output transferable? Can it be plugged directly into a third-party agent builder, API, or automation pipeline with minimal transformation?
Does the output encode intent and decision logic (“why” something happened), in addition to behavioral telemetry (“what” happened)?
Can the system successfully handle edge cases and variability, recognizing when different actions are targeting the same end goal?
Step 3: Setting up the feedback loop
Output from Step 2 flows back into the product. This is typically done through either: (i) context enrichment (prior data and observations are stored and organized in a way that helps agents easily find and access in future sessions), or (ii) model adjustment and fine-tuning (interaction data and output is used to retrain the models doing observation in Step 1 and conversion in Step 2).
04 | Externalization, industrialized
Nonaka understood that a company’s real competitive edge comes from externalization – the ability to convert human intuition and craft into something others can use. In 1991, this was done through language and human dialogue.
“The three terms capture the process by which organizations convert tacit knowledge into explicit knowledge: first, by linking contradictory things and ideas through metaphor; then, by resolving these contradictions through analogy; and, finally, by crystallizing the created concepts and embodying them in a model, which makes the knowledge available to the rest of the company.”
- Ikujiro Nonaka, The Knowledge-Creating Company (1991)
For Nonaka, externalization was always gated by human bandwidth – the slow work of conversation, management, and mentorship.
But AI removes that constraint. The products discussed in this piece take the raw, unstructured mess of how people work and convert it into semantic meaning.
It's externalization, industrialized.
The products that win today won’t succeed with "better AI" or "better agents." They will develop a new sensory layer for work – one that observes what no system has ever recorded, translates it into meaning machines can read, and allows that knowledge corpus to build organically over time.
The companies that get this architecture right won’t just survive the next model release. They’ll get stronger from it.
They'll bring the dark matter of work into the light.
Git is an open-source version control system designed in 2005 (the company Github is a collaboration layer built on top of this framework). Git stores code as blobs (raw text of code with no metadata), organized into trees (folder hierarchies) and commits (snapshots of the entire repo), all linked in a directed acyclic graph (DAG) that records how the codebase evolves. Every commit points to its parent, enabling Git to trace parallel branches to their common ancestor and reconcile textual differences line-by-line.
An IDE (integrated development environment) is the application where software developers write, edit, and test their code. This includes tools like VS Code or Cursor.
A commit is a snapshot of changes saved to a codebase — think of it as a developer pressing “save” on a batch of work, with a short note describing what changed.
Robotic process automation (RPA) is a category of software that automates repetitive, rule-based tasks like data entry, form filling, and moving information between systems.
Distillation is a technique where a smaller model is trained to replicate the behavior of a larger, more capable model, compressing its knowledge into a form that's cheaper and faster to run.
Quantization is a technique that compresses a model’s numerical precision – e.g., from 32-bit to 4-bit values – dramatically reducing its memory footprint and compute requirements while preserving most of its performance. It’s one of the key techniques enabling large models to run on consumer hardware.