
Three Theses

Venture capital is crowding into a handful of names. But the innovation potential is wider than this trend suggests.
This post offers an alternative framing of the next phase of software, and three startup ideas that follow:
A. AI-native e-commerce, rebuilt around a single intelligence layer
B. Dev tooling that translates product taste into code
C. Data and risk layer for physical AI
If you’re building in one of these areas, or something adjacent, I’d love to connect.
01 | The fog of AI
We’re three or four years into the AI cycle, and capital has rushed in with unusual intensity.
For the past couple of decades, the top 5 U.S. venture deals in any given year typically represented anywhere between 2-10% of total capital invested in the asset class.
In 2025, that number climbed to 24% of the total.
So far in 2026 – nearly 70%(!)
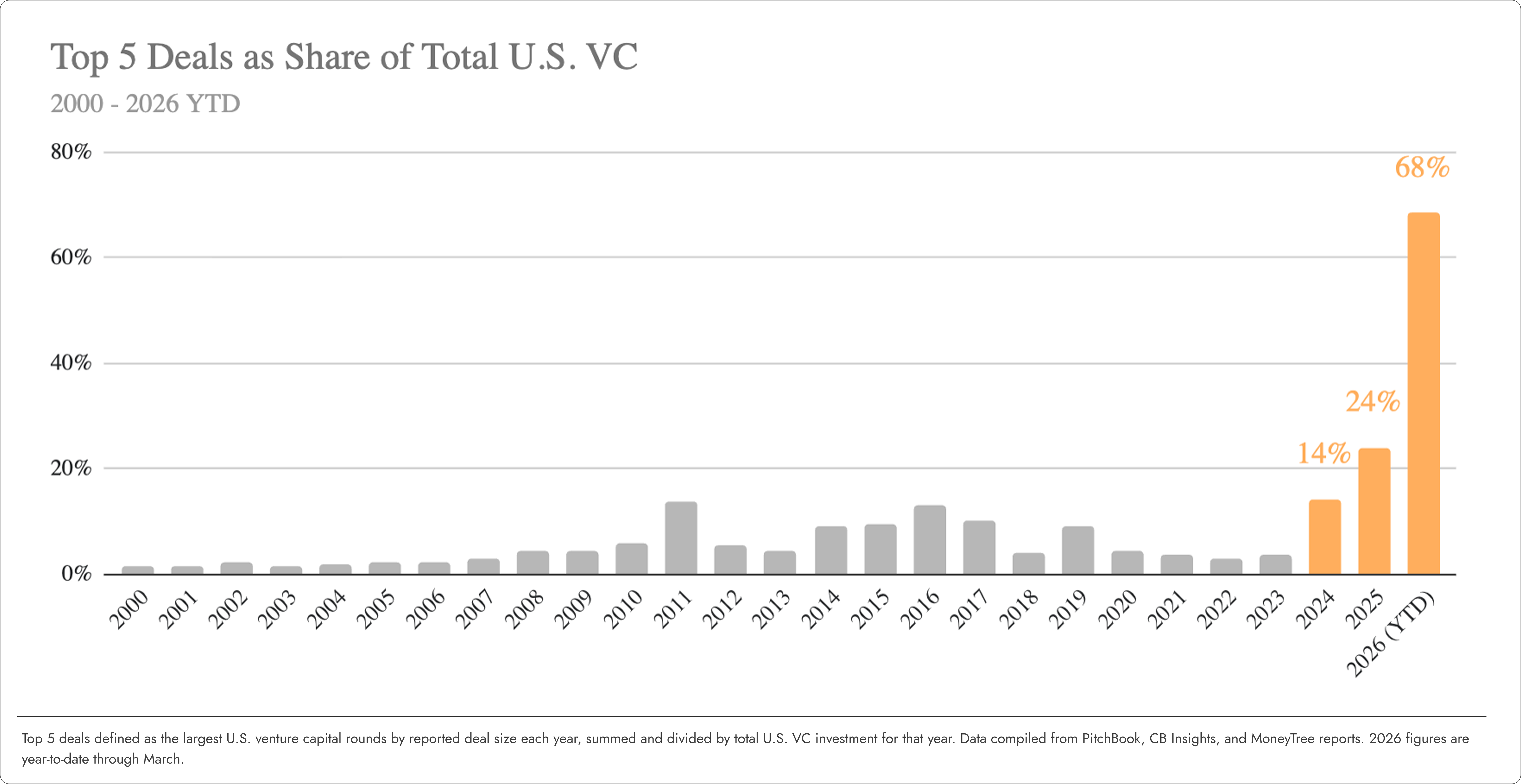
To put that in context... in real dollars, early AI companies have already surpassed the total lifetime equity raised by Google, Facebook, Apple, Amazon, Microsoft, Nvidia, Tesla, and 21 other leading tech businesses – combined.

Whether AI’s technical fundamentals support these deployment patterns remains an open question.
But this isn't the only way generational companies get built. Most of the defining companies of the last two cycles raised a fraction of what today’s AI leaders have, and they created extraordinary value.
Yes, times have changed. Capital markets are more competitive, timelines have compressed, and AI’s unit economics may not comp cleanly to past cycles.
But there’s a lesson in the data. Money isn't the scarce input in company-building.
Capital only amplifies a great product, it cannot create one.
Three or four years into AI, the fog is starting to lift. We understand more now about how this technology is built, what it can reliably handle in production, how it scales, and how it gets adopted. The surface area for innovation is much wider than where capital has pooled so far.
The AI story is far from written.
02 | Software isn’t dying
The evolution of software is essentially a long-term project in making computers easier to talk to.
Computer programming started at the level of bits (1s and 0s), then moved to machine code, then to foundational languages like FORTRAN, then higher-level ones like Python and TypeScript.
Each transition moved us up the ladder of abstraction, bringing programming closer to how humans think and hiding the technical friction of the layer below.
AI moves us up another layer – from code to intent. Instead of running pre-written commands, the user only specifies an objective, and the machine handles the rest.
More specifically, AI is changing software in three fundamental ways:
#1 Deterministic → probabilistic
Software will now produce a distribution of outcomes, rather than executing a pre-programmed path.
#2 Human-operated → agent-operated
A growing share of software interactions will be initiated by machines, with humans as orchestrators.
#3 Fixed → malleable
Software will be generated and customized on-demand directly by the end-user rather than the vendor.
Moats now have to come from what raw intelligence cannot recreate on its own. For example, accumulated memory and context, instrumentation that turns activity into a new type of data asset, or new distribution models that bypass one-to-many channels like SEO and app stores.
Software isn’t going anywhere. It's just abstracting upward, the way it always has. It’s taking a new shape, with new sources of defensibility underneath.
If AI makes software easier to talk to, I expect we'll see a lot more of it.
Below are three ideas that follow from this view.
This post is in part a broadcast, to find like-minded founders working on these problems.
But it’s also a creative exercise. A chance to set aside the “end of software” and “AI will commoditize everything” narratives for a moment and to imagine the products that could drive long-term value in this new paradigm.
Thesis A: An e-commerce brain
Shopify (NASDAQ: SHOP, $156B EV) and Amazon (NASDAQ: AMZN, $2.8T EV) represent opposing strategies in online commerce.
Shopify gives merchants full ownership of brand, customers, and data. Each shop runs independently, merchant data stays siloed, and discovery happens off-platform through SEO and paid acquisition. Shopify never aggregates shopper demand to put merchants in competition with one another.
Amazon does the opposite. They standardize the buyer experience, control the platform end-to-end, and use merchant data to optimize the marketplace. Merchants are inventory feeders, with little control over their brand and data.
Both companies have started retrofitting for AI. Shopify now lets stores syndicate products into ChatGPT and Gemini and recently launched merchant-side AI tooling to automate store operations. Amazon launched their AI shopping assistant Rufus for product discovery. Each has adopted standards like ACP and UCP1 to streamline agent-driven transactions.
But both are bolting AI onto an architecture that keeps buyer and seller context separate.
AI is only as smart as the information you put in front of it. You can stitch buyer and seller data together at the moment of inference. But product discovery and matching get sharper and cheaper when both sides live in the same ecosystem.
The opportunity is to build the first AI-native commerce platform where buyer, product, and merchant context live in a single, shared memory graph. One substrate that both sides read from and write to continuously.
This unlocks deep personalization and automation at scale – a personal shopping assistant for users, and a modern operating system for merchants:
Merchant. A new shop owner types “Launch a new pottery store to sell my work.” The system runs structured onboarding to build the store, assembling the store with the best tools for each task – e.g., Lovable for storefront design; Gemini for creative assets; custom agents for BI, inventory, and customer support. Running the shop happens through natural-language commands – “raise prices on mugs 10%,” or “summarize sales this week.” The merchant focuses on brand, product, and strategy. The system handles the rest.
Buyer. Each user is assigned a personal agent that learns the shopper over time – body type, fit, taste, brands they love, returns and why. The shopper profile deepens through natural conversation – e.g., “Buy from sustainable brands,” or “show me items in this color palette,” uploading a reference photo. The ecosystem becomes a destination, a place you go to connect with your digital concierge.
Shared memory. Every interaction from shoppers and merchants – query, click, purchase, return, store redesign – writes to the same context graph, capturing rich semantic context for every entity in the ecosystem. With more data and use, the graph compounds into the most valuable asset in the network.
Discovery network. After a shopper query, a retrieval layer narrows the catalog to a smaller candidate set. An LLM then reads buyer and product context and reasons to determine fit. The match is grounded in why this product works for this person, not in how similar buyers behaved.
This redefines the distribution and business model for online shopping.
Today’s half-trillion dollar digital ad industry is really just a workaround for siloed data – a guessing game that understands buyers and products separately, then tries to match them at query time.
When discovery is grounded in real fit and deep context on both sides of the market, the network can monetize satisfaction and loyalty – not ad placement or click-through rates.
Thesis B: Automating product taste
For fifty years, software was built to deliver certainty.
Developers wrote instructions in code, specifying exactly how an application should perform. The same input was designed to produce the same output every time.
Because of this predictability, we sliced the software development lifecycle into discrete, sequential stages – plan, write, test, deploy, monitor. Value accrued to the companies that owned the artifact produced in each step. Jira owned the ticket. GitHub owned the commit. Datadog owned the log.
AI-native software inverts this.
Uncertainty is a core property of LLMs. The same prompt to the same model yields a distribution of plausible responses. “Good” output is a moving target that shifts with new user behavior, context, and model improvements.
Today, developers try to impose certainty on AI by wrapping the model in scaffolding, using techniques like prompt templates, hard-coded guardrails, handwritten eval sets.2 Existing LLM observability platforms like Braintrust and LangSmith support this work by giving a window into model performance, but they rest on a faulty premise – that humans should still draft and run evaluation as a discrete step in a workflow.
In a world of model variance, where software “behavior” is constantly shifting, that becomes a bottleneck.
AI systems instead need a self-orchestrated loop – real-time, automatic evaluations that keep performance aligned with developer intent. Taste – the judgment about what “good” product performance looks like – has to be encoded in the system itself, not maintained by humans from the outside.
The target product is a gateway proxy between the application and its model providers. Prompts, responses, tool calls, and metadata flow through it. Behind the gateway are two components:
(1) Autonomous evaluation. The system generates its own rubrics from three inputs – the application design, live user behavior, and the full execution trace of each model call. Every call in production is scored against the rubric, which self-refines as the system learns which configurations correlate with successful outcomes.
Auto eval is difficult to build. LLM judges can already match humans on many evaluation tasks, but auto-generated rubrics still underperform human-authored ones. Closing that gap is the core technical bet.
The good news is this has become much more feasible in the last 18 months. For example, research on scalable rubric generation points toward a future where the data flowing through a product like this could continuously refine the rubric layer.
(2) Tiered remediation. When behavior drifts from intent, the system can take action – rerouting, retrying with different context, or alerting the developer with a natural-language explanation.
This product treats evaluation not as instrumentation the developer bolts on, but as something invisible, automatic, and always on. The product is working if the engineer never has to write the full rubric directly.
The moat is the data model.
In this product, each rubric criterion is a first-class entity that links to outcomes and refines automatically as the system learns which criteria predict success. Over time, the rubric becomes deeply attuned to the specific application. The result is a custom, self-improving evaluation layer that's difficult to rip out.
Building this is no small technical feat. But the team that gets it right will encode product taste, turning it from a craft engineers practice from the outside into a native property of software itself.
Thesis C: Risk layer for robotics
By 2035, autonomous systems are projected to represent a multi-trillion-dollar opportunity, with autonomous vehicles and robotics as the largest segments.
Commercial deployment of these assets demands a fundamental rethinking of how to analyze and price risk.
Traditional insurance assumes risk is a function of human behavior. Actuarial models analyze historical claims and demographic data, and assume behavior stays statistically consistent over time.
But when the “driver” is software, that breaks. Risk needs to be measured continuously, by technical inputs like software version, perception quality, the decision-making policy, and whether the system is operating inside the conditions it was designed for.
The incumbents – Verisk (NASDAQ: VRSK, $26B EV), Relx (NYSE: RELX, $72B EV) – have built their products and customer relationships around episodic claims. Analyzing risk from telemetry streams is a different problem entirely, and would require an overhaul of their infrastructure.
There’s an opportunity now to build something from scratch.
The target product is an API-first middleware layer. A lightweight agent installed on the autonomous asset ingests live telemetry (sensor health, perception logs, near-miss data), runs it through in-house AI/ML models, and generates dynamic risk scores for carriers and operational insights for fleet operators.
With a first-mover advantage, this platform can set the schema and actuarial foundation the entire category prices against, similar to the role ISO’s loss costs3 play today for property claims. Once a large enough dataset is amassed, multiple business lines follow – analytics to operators, revenue on claims forensics, licensed data to physical AI companies for training.
The winning product unlocks data network effects.
For example, if the platform learns that a specific LiDAR4 blockage pattern predicts crashes in delivery robots, it can price the same failure mode in farm equipment immediately, without waiting years for new claims. As more fleet types contribute data, underwriting improves, adoption accelerates, and the data edge compounds.
Autonomous fleets cannot deploy at scale without insurance, and carriers cannot underwrite without telemetry. The platform that resolves this standoff has the opportunity to establish itself as the de facto standard – and make our warehouses and factory floors safer along the way.
Many of these early AI titans are building extraordinary technology. Whether the capital flowing to them reflects durable value or cycle dynamics, time will tell.
But what I do believe is that the opportunity beyond them is enormous.
AI, after all, is not a product in and of itself. It’s a precondition. Raw material. And there’s still an enormous amount of shaping left to do.
Agent Commerce Protocol (ACP) is an open specification co-developed by OpenAI and Stripe that lets AI agents complete transactions on behalf of buyers. Universal Commerce Protocol (UCP) is an open standard co-developed by Google and Shopify that defines how AI agents discover products, manage carts, and complete checkouts across merchant backends.
Prompt templates are reusable scaffolds that structure how a model is asked to do something. Guardrails are rules that constrain what the model can output (filtering for tone, blocking topics, enforcing format). Eval sets are curated test cases used to check whether changes to a prompt or model improved performance. For a good primer on evaluations, click here.
ISO (Insurance Services Office, now part of Verisk) publishes standardized “loss cost” data – historical claims experience aggregated across carriers – that most property and casualty insurers use as the actuarial baseline for pricing their policies. It’s the de facto reference layer for the industry.
LiDAR (Light Detection and Ranging) is a sensor type that fires rapid laser pulses to measure distances and build a real-time 3D map of the environment. It’s a core perception input for most autonomous vehicles and robots.