
Can the AI Boom Pay for Itself?
The Math Behind the Mania

Investment in AI infrastructure is accelerating. This issue analyzes whether demand for the technology will keep pace.
UPDATE - NOV 2025
I’m now tracking AI token consumption in real time. View the live tracker here →

For updates on this tracker and fresh analysis on other emerging technology trends, subscribe below.
01 | The rhythm of exuberance
In 2000, the Internet looked unstoppable.
Telecom carriers poured over a quarter of revenue into fiber networks, betting Internet traffic would double every three months. Market concentration spiked, as investors believed control of infrastructure would cement long-term advantage. The Shiller CAPE ratio, a measure of how expensive the stock market is relative to historical earnings, hit an all-time high of 43.8 (more than double the average of the prior 15 years).
Then the dominos fell.
Network utilization lagged. Prices collapsed under excess capacity. Telecom carriers, who had booked revenue from leasing unused fiber to one another, were forced to write down these receivables as losses. Defaults rose. Equity values deflated.
By 2002, only 2.7% of installed fiber was in use.
The modern Internet – cloud, streaming, big data, mobile – eventually arrived. But not fast enough to prevent a correction.
History doesn’t repeat itself, but maybe it’s starting to rhyme. Big Tech is investing big in AI infrastructure, and investors are buying.
On inflation-adjusted basis, capital expenditures are now roughly twice the level at the 2000 peak. The six largest tech firms now make up over 30% of the S&P 500, double the concentration we saw in 2000. The CAPE ratio is the second highest it has ever been.
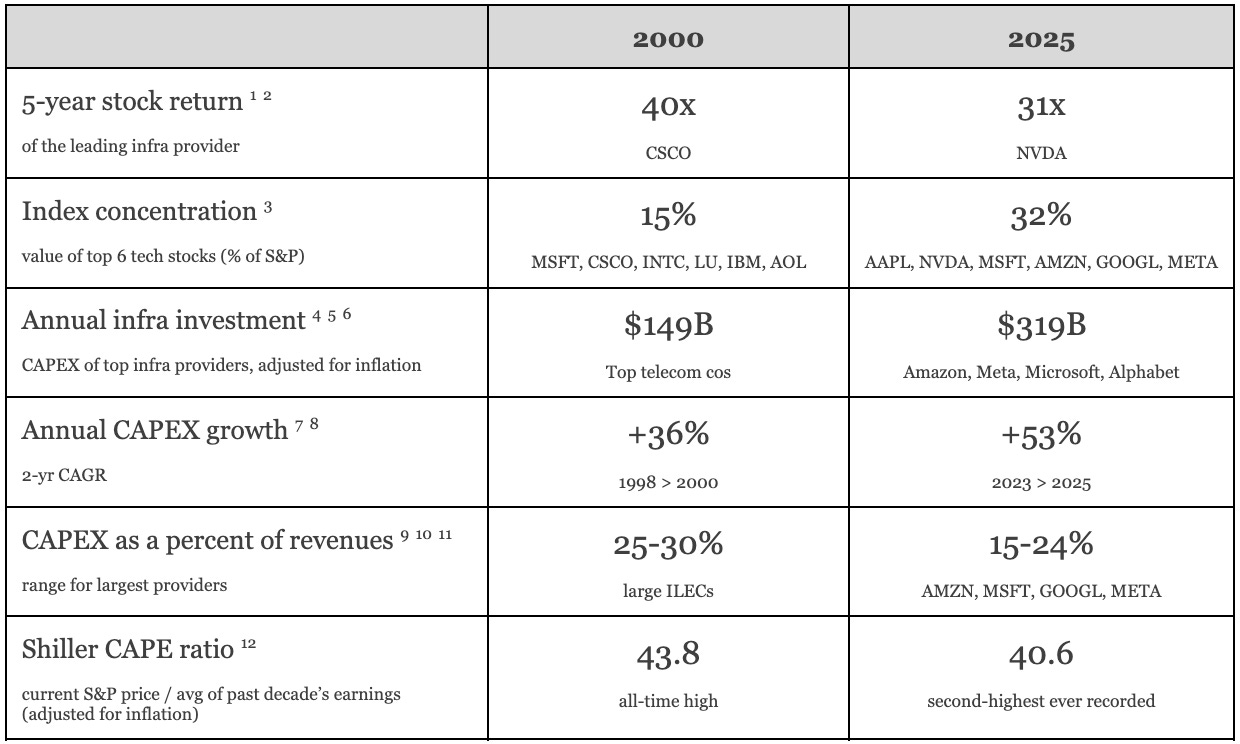
Footnotes: 1 2 3 4 5 6 7 8 9 10 11 12
Of course, comparing 2000 to 2025 isn’t apples-to-apples.
In 2000, investment went into networks of fiber and routers, long-life assets financed mostly with debt.13 Today’s infrastructure – GPUs and servers – depreciates faster, and is funded by cash-rich tech giants (though some leverage is making its way into the system). And unlike in 2000, today’s market is concentrated around firms with real, 15+ year moats in distribution, data, and developer ecosystems.
Still, it’s hard to ignore the parallels:
Big Tech is investing ahead of demand, on the premise that:
demand for AI will soon rapidly permeate the real economy
scaling compute is necessary to maintain a competitive advantage in AI (new MIT research disputes this, showing steep diminishing returns to additional compute and convergence of model capabilities over time).
Market power is highly concentrated.
Circular financing is back: Chipmakers, cloud providers, and model labs are funding one another through prepaid deals, minimum-spend guarantees, off-balance-sheet projects, and direct debt and equity positions — arrangements that can inflate real demand.
AI Ecosystem Capital Flows14
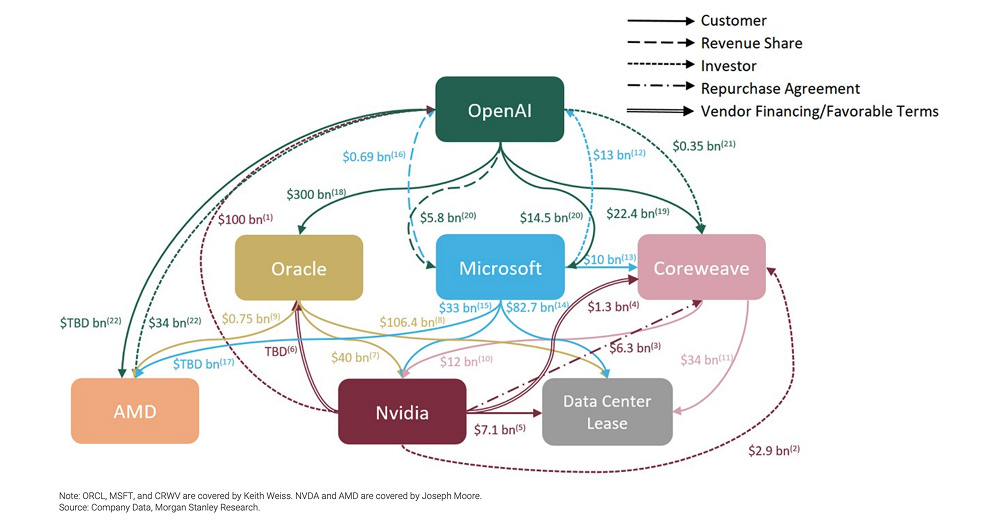
Fundamentally, both cycles rely on the same underlying premise → real demand will surge before the bill comes due.
02 | Can demand keep up?
This context raises two important questions:
How much – and how fast – must AI usage grow over the next several years to justify today’s investment?
Is current demand roughly on pace?
I built a simple model to answer these questions. (Take the results as ballpark figures, not precise forecasts.)
For this analysis, I measure AI demand in inference tokens.
A token is the basic unit a model uses to process data – think of them like kilowatt-hours for electricity. Inference refers to tokens used to generate a response to a new user prompt, as opposed to tokens used for training or model development.
To estimate how much AI usage must grow to justify current investment, the model links infrastructure spending to inference token demand in four steps:
1. Direct CAPEX spend. The projected spend on GPUs, servers, and compute hardware – assets that directly power AI token consumption. This excludes indirect inputs (e.g., investment in real estate, site development, and energy systems). I run these projections in two scenarios – (1) an aggressive buildout, based on analyst estimates, and (2) a conservative “boom-and-bust” case that mirrors the dot-com-era investment cycle.
2. Requisite revenue. The annual customer revenue needed to generate a sustainable return on investment for each scenario. This assumes industry norms around overall asset and inference utilization, depreciation, and CAPEX-to-revenue hurdle rates.
3. Blended token price. Estimated from OpenAI, Anthropic, and Gemini list pricing, factoring in standard input-to-output token ratios, how prices have scaled over time, and patterns around how users upgrade to the latest model.15
4. Token volume. Dividing the required revenue by the blended token price yields an estimate of how much AI usage would be needed to justify the build-out.
Based on this, an aggressive, $3.1T buildout over the next 5 years implies AI usage must compound at 2.8x every year through 2030. A more conservative $1.3T path still requires 2.5x annual growth.
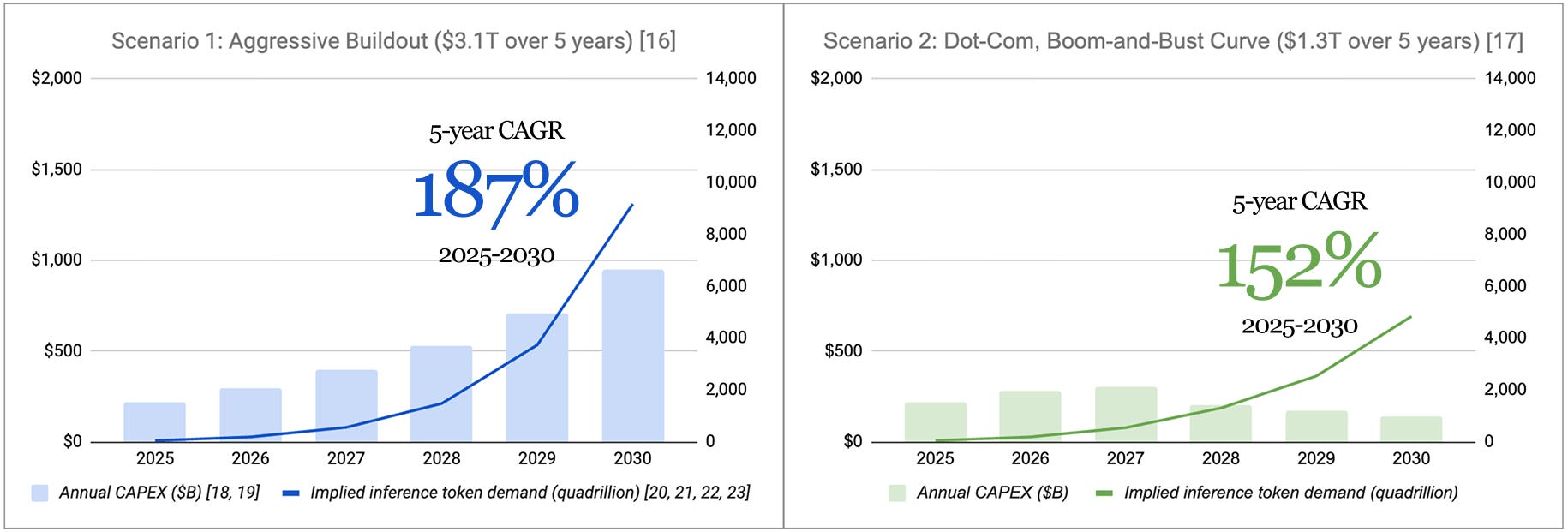
Footnotes: 16 17 18 19 20 21 22 23
To put this in context, both scenarios would require a steeper adoption curve than any prior tech cycle, including the early internet, mobile, and cloud.
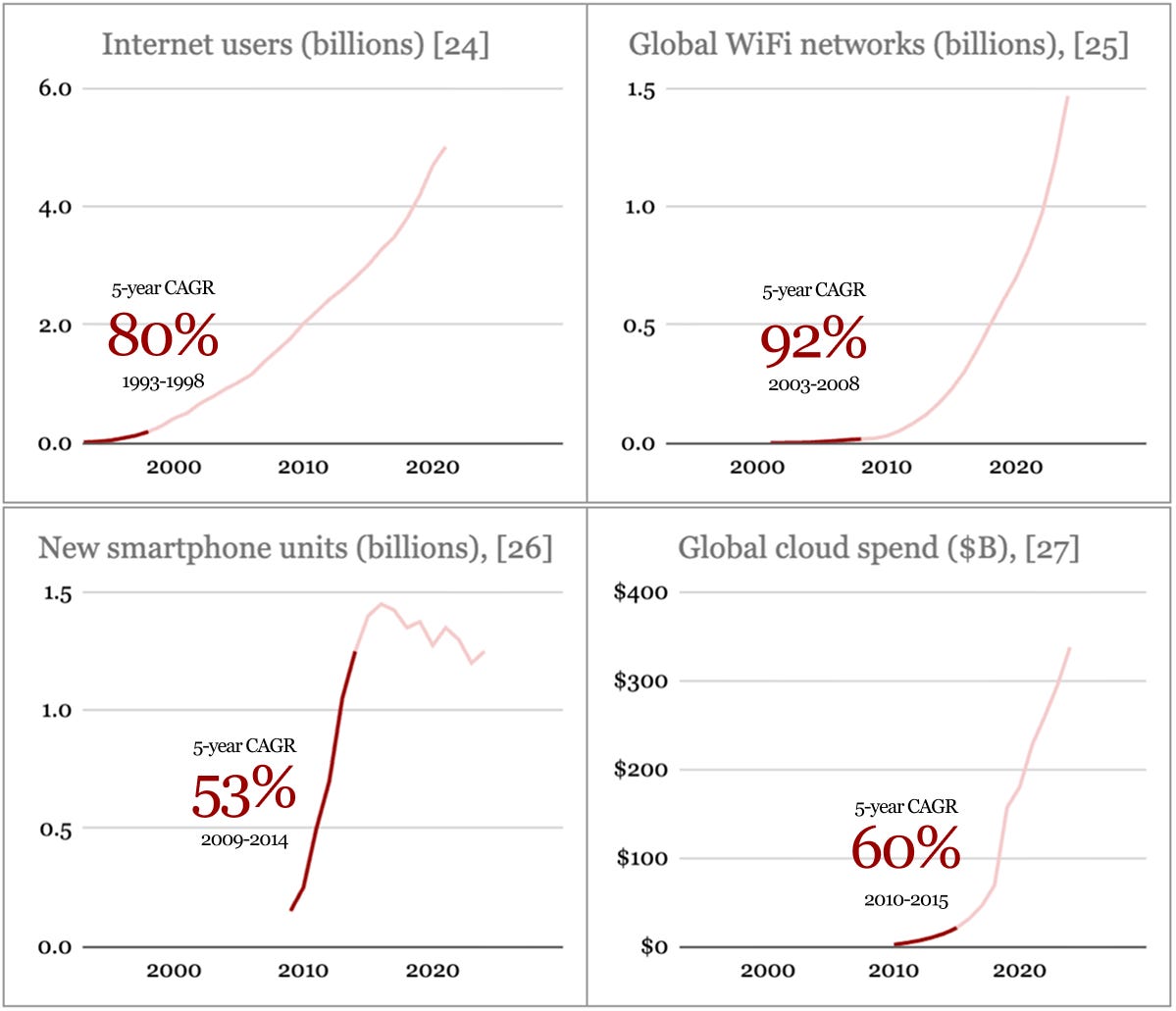
Footnotes: 24 25 26 27
Yes, this would be unprecedented growth. But it is not impossible to imagine when you consider the maturity of our digital landscape.
Today, AI can be shipped through existing products – SaaS, app stores, browsers – that billions of people already use. It can plug into workflows with a simple API call, running on cloud infrastructure that abstracts away hosting and scale.
With distribution this wide and deployment friction this low, adoption certainly could happen faster than we’ve seen before.
03 | A question of timing
So far, AI consumption is tracking well against these curves.
Both modeled scenarios require a ~9-12% cumulative monthly growth rate in inference token consumption over the next couple years. Microsoft is currently tracking to 14%,28 and Alphabet saw 15% per month from August to September (although that is down from 31% CMGR in the prior ten months).29
It is still too early to know for certain whether we are on the right trajectory. I’m monitoring three developments that could indicate an impending correction:
(1) Token growth. On an absolute basis, inference token demand is still within target. But over the past couple months, there’s been a deceleration. Watch the next few earnings calls. If monthly token processing falls consistently below 9-10% growth, or if companies stop disclosing the metric altogether, it may suggest the market is over-committed.
(2) ROI in the real economy. AI still needs to prove wide, durable value beyond chatbots and coding assistants — and fast. Many enterprise deployments aren’t yet showing measurable ROI. On the consumer side, usage is heavily subsidized (only ~5% of ChatGPT’s users pay). These dynamics aren’t unusual this early in a tech cycle. But risk will build as more capital piles into the hardware layer – especially into assets whose economic life may be shorter than what is being reported to shareholders.
If model labs keep emphasizing new releases, benchmark scores, and pilot announcements while remaining quiet about large-scale production deployments and customer renewals, it could signal that adoption in the real economy is lagging behind the hype.
(3) A break in scaling patterns. This analysis assumes model performance scales in tandem with compute and data. A step-change in AI efficiency could break this pattern – e.g., if an entirely new model architecture emerges that requires far less compute to achieve the same performance, or if smaller/open-source models prove more effective than large-scale proprietary ones for specific use cases.
Today, 13% of AI workloads run on open-source models. Whether that share rises or falls will be telling.
I’m also tracking platforms like Fireworks and DeepInfra, which simplify deployment of smaller and open-source models. If those platforms grow faster than the overall inference market and capture developer mindshare, it would suggest that near-term demand can be met with lower-cost solutions — thus reducing the need for major new infrastructure spending.
Netting it all out, I think we are likely in an over-investment phase.
Inference token consumption is growing well, but there are signs it’s starting to slow. Most AI-native products are good for individual productivity in coding or writing, but fall short on full workflow automation or enabling real collaboration. If that persists over the next 12-18 months, it could cap near-term demand.
This view tracks with researchers like ex-OpenAI’s Andrej Karpathy, who argues reliable, agentic systems “just don’t work” yet, and will arrive through a steady, multi-year build — not overnight.
If there is some over-investment today, that might be good news for startups. Historically, when infrastructure supply runs ahead of demand, the next wave of value usually comes from networks and coordination that can be built on top.
After the 2000 fiber glut, TCP/IP and HTTP standardized communication over the internet, turning surplus bandwidth into the interconnected web. In the big-data era, open frameworks like Apache Hadoop enabled more efficient coordination between data storage and compute workloads, unlocking idle server capacity.
AI could be on the cusp of a new coordination layer.
Right now, there’s a quiet wave of new interoperability standards coming to market. These frameworks have the potential to translate raw model capability into cohesive, multi-agent systems – creating new ways for agents to communicate, share context, and compose workflows together. Startups that can commercialize and scale these protocols have a chance to build the control layer for networked intelligence, turning individual agents into a functioning economy.
Next post, I take a closer look at emerging multi-agent standards – what they are, how they work, and the market and network dynamics they could unlock.
Shiller PE ratio for the S&P 500, based on average inflation-adjusted earnings from the previous 10 years. Shiller PE ratio by year.
Telecom carrier debt peaked at $300 billion in 2000.
Even though consumer subscriptions (e.g., ChatGPT Plus) aren’t billed per token, for simplicity, this analysis assumes that subscription and API pricing effectively average out to similar unit economics, since both rely on the same GPU capacity and cost structure.
The aggressive, $3.1 trillion direct CAPEX case is anchored in McKinsey’s estimate that “technology developers and designers” (chips and compute hardware) will require roughly $3.1 trillion through 2030. This aligns directionally with NVIDIA CEO Jensen Huang’s recent claim that hyperscaler AI-infrastructure spending is already trending toward $600 billion annually.
Bear case follows a dot-com-era CAPEX growth curve.
Sustainable CAPEX-to-revenue ratio of 4x and straight-line depreciation over 6 years. Note that several hyper-scalers recently extended estimated useful lives for servers/network gear to 5-6 years – Alphabet to 6 years; Microsoft to 6 years; Meta to 5.5 years – whereas datacenter GPUs themselves often have shorter service lives (possibly 1-3 years at high utilization). Using a 6-year schedule introduces risk if hardware must be retired or replaced sooner than the booked period.
Blended token price is derived from current and historical list rates across OpenAI, Anthropic, and Gemini, assuming:: (i) a 3:1 input-output token ratio, (ii) 66% of tokens are served on frontier models, and (iii) a 50/50 split between pay-as-you-go and batch/committed plans (where available). Even though subscriptions like ChatGPT Plus aren’t billed per token, they still consume the same GPU capacity. For simplicity, this analysis assumes roughly similar unit economics.
Assumes a three year inference utilization schedule, 50% in Y1, 80% in Y2, 90% in Y3, reflecting ramp-up patterns as infrastructure utilization stabilizes.
Alphabet has reported processing 480T, 980T, and 1,300T inference tokens in May, Jul, and Sept 2025 respectively. Although this increase has largely been attributed to computational effort, not user value, as Google’s latest model Gemini 2.5 Flash uses approximately 17 times more tokens per request than earlier versions and costs up to 150 times more for reasoning tasks.
This article comes at the perfect time. The parallels with 2000 are just realey wild. What emerging standards could actually avoid this trap? Such an insightful analysis!