
The Erosion of Rented Intelligence
A Conversation with Fireworks Co-founder Benny Chen

There’s a paradox in Silicon Valley.
The industry celebrates contrarian thinking. Yet so often, the underlying mechanics – social proof, the pace of capital deployment, the pull of the power law – bias toward consensus.
Benny Chen strikes me as an exception. A founder who reasons from first principles and follows his conviction, independent of market sentiment.
Three years ago, Benny and several members of the team behind PyTorch – one of the most widely used frameworks for building neural networks – left Meta with the insight that enterprises would want to own their AI, not rent it.
In 2022, most did not see the world this way.
The prevailing wisdom said frontier AI capabilities required incredible scale and deep pockets. Most assumed the next generation of AI applications would be built on closed, general-purpose models from labs like OpenAI and Anthropic.
Benny and the team believed something different, that companies would want AI they could more directly customize and control.
So they built Fireworks, a platform that lets companies take open-source AI models,1 train them on their own data, and deploy them with speed and efficiency.
The world is now catching up. DeepSeek proved open-source models could compete at the frontier. Today, open models deliver ~90% the performance of closed-models — at one-sixth the cost.
Fireworks is riding this wave. The company processes 13T tokens daily (the same scale as Gemini’s developer API) for over 10,000 customers, including Uber, Shopify, and Notion. This October, three years after launch, they crossed $280 million in annualized revenue.
I sat down with Benny to discuss:
Why he believes demand for open-source AI is about to hit an inflection point.
How enterprises can exceed frontier model performance – with only 100 rows of data.
Predictions for AI in 2026.

01 | Frontier models ≠ frontier capabilities
EO: Tell me about the decision to launch Fireworks.
Back in 2022, many people assumed that the future belonged to the big, closed model labs. Billion-dollar investments in training and compute were considered the price of admission.
What gave you the conviction to go the other direction, to build a company around open-source?
BC: Focusing on open-source and inference2 may have been contrarian to others. But to us it was very clear.
When we started, there was no ChatGPT. But we’d supported a lot of internal AI models in production at Meta, making sure workflows scaled economically.
Because of that experience, we believed most value in AI would come from inference.
We decided to build a company that helps developers deploy best-in-class AI profitably, and then we take a cut. That, we believe, is a more sustainable business model than raising huge amounts of money to come up with frontier models.
I think Sam Altman once said artificial general intelligence (AGI) could capture the “light cone of all future value” – that OpenAI is playing to capture all of humanity’s future economic value.
That’s an interesting proposition – that if you have a monopoly, no one else can ever figure out how to take it. I don’t think that’s ever been true in the history of capitalism. If there’s enough profit, someone will figure out how to compete.
But the predominant narrative is you have to raise a lot of money to stay at the frontier, and that developers will always demand frontier capabilities for their products to stay competitive.
It sounds like you believe something different.
I think “open-source” is just a fancy term for “sharing the burden” – a bunch of people opening up what they did so others can replicate it without making the same mistakes. And if you have tens of thousands of GPUs running in the background, mistakes are very costly.
Eventually, we believe people will act rationally. And sharing the burden for these costly endeavors is normally the rational thing to do.
By “act rationally,” you mean stop focusing as much on model capability, and more on cost?
Absolutely. One day, reality will hit. Cost will eventually become important. Everyone will have to figure out how to stay in business under those constraints. If you’re honest about that on day one, your business model will be much cleaner in the long run.
The other part of your question was whether enterprises will demand frontier capabilities. Yes, they will. But just because they need frontier capabilities does not mean they need frontier models.
Fireworks works with startups like Genspark to build custom evaluation suites,3 then use our training platforms – we call them reinforcement fine-tuning (RFT)4 platforms – to plug those evaluations in. This gives our customers frontier AI capabilities, but with open-source models.
When we do that – when we set up the data flywheel properly – “frontier model” and “frontier capability” are decoupled.
We believe that’s more sustainable. Because even if frontier models can see the traffic you’re sending them, they don’t know how the developer defines success for their specific use case.
That production data feedback loop — knowing what success looks like and how your product performs against that — that’s something application developers have that the model labs never will.
We are helping the builders who have that data.
02 | “Open-source models are about to take over.”
Help me make sense of the market as it pertains to open- vs closed-source.
On the one hand, open-weight models offer near parity on raw performance, at a fraction of the cost. For example, customers who move to your platform see an 8x average cost reduction.
So the value is there, but adoption less so.
In aggregate, these models only power 11% of total workloads – and that’s down from 19% last year.
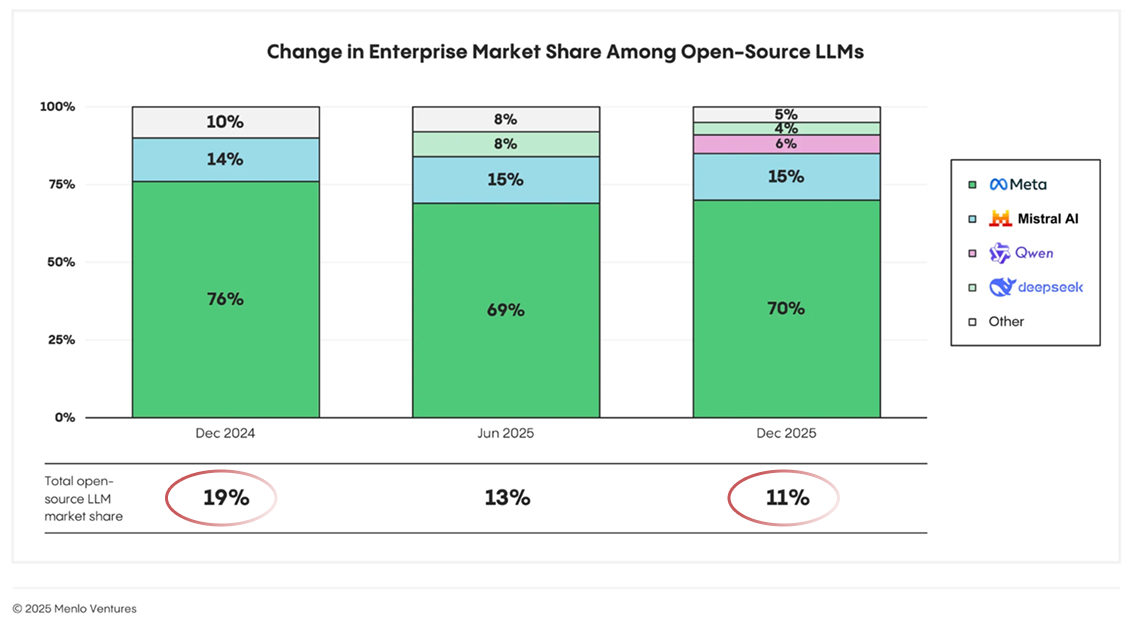
How do you interpret all this?
Let’s break it down, around specific capabilities.
When it comes to software engineering, closed models are way ahead. You may not see that in benchmarks. But if you use these coding tools on a daily basis, you can tell – closed is much better. Within coding, Anthropic is the undisputed king.
Coding was the first killer use case for AI, and still represents a significant portion of total spend. Which is why closed models still dominate overall.
Open-source is also behind in multimodal understanding. That’s where Gemini is amazing, much better than everyone else at image recognition and video understanding.
Aside from those two domains — coding and multimodal — open and closed models are pretty close. Right now, there’s a level of performance that closed models deliver. But open-source models are catching up to that.
A lot of companies are considering both. They may be using closed right now, but open is very close in terms of capability. And when it flips, it will flip very quickly. I think open-source models are about to take over.
That’s a big statement. Why do you think that?
We work with a lot of application developers. And for non-programming use cases, the open models are already very close or better.
And by “non-programming use cases,” you mean tool calling and multi-step workflows?
Yes exactly.
A good way to understand it… For tasks where models aren’t yet 100% reliable – for example, software engineering, which is maybe at 20-30% today – you’ll always want the latest and greatest model. You want every advantage you can get.
But for workloads where there is a way to hit near-100% accuracy – and open-source models are starting to saturate those benchmarks – it’s more about usability, quality, and cost. That’s where open-source will win every time.
Is there a reason why the frontier labs are so much further on coding and multimodal understanding? And how sustainable is that paradigm?
With coding, Anthropic’s leadership is focused on programming use cases. The money they spend on acquiring data, environments, and evaluations are all very directed at coding. I respect that, focus is everything.
For multimodal, Gemini has YouTube. No one else has access to that kind of data.
Whether they maintain this edge is up to execution. It’s very hard to predict that, but my guess is they continue to do those very well.
So is there a scale or threshold where open-source starts to become more interesting for an enterprise customer?
Scale is one aspect. At Fireworks, we can deliver lower total cost of ownership5 with open-source.
The other aspect is self-sufficiency. The founders at these model labs have ideologies and constraints they impose on their model behavior. And so self-sufficiency is a big reason why people come to Fireworks.
By self-sufficiency, you mean they demand a level of customization they’ll never get with closed models?
Yes. With their own evaluations and model customization, they can control their own destiny.
One way to think about it… imagine if every business only had one supplier. That makes no sense. You want multiple suppliers throughout your supply chain. So companies see that risk, and they want to mitigate it.
Self-sufficiency through open-source keeps all partnership and M&A exit doors open for your company.
03 | Opening up the playbook
Fireworks RFT is a managed service that lets enterprises fine-tune open-source models, using reinforcement learning.
Fireworks describes it as giving developers “the same playbook frontier labs guard so closely” – but now applied directly to their own workflows and data.
How exactly does RFT deliver performance that can match or beat frontier models, like Claude or Gemini?
RFT is effective because of sample efficiency. You can customize a model with only 100 rows of data.
Developers are busy. If you tell them they need 10,000 rows of clean data to get started, they know that’s a day job for ten people to label the data, run quality control, etc. No one will do that.
But these developers are already collecting failure cases as they build their applications. They are constantly comparing new versions of Gemini, Claude, and GPT in their software. This means they often already have evaluation suites with 50-100 examples. Moving those directly into reinforcement learning is very straightforward.
On top of that, Fireworks offers a managed service that handles the correct defaults6 for developers – numerical consistency, tokenization, GPU failure recovery, etc.
How do you scale that service across such a diverse customer base?
Developers are building agents in different languages, frameworks, and environments. RFT only works if we can connect to all of these different agents without asking developers to rewrite their code. As a general principle, if you want to help everyone standardize around a particular methodology, it has to be built in the open.
So we released Eval Protocol (EP), an open-source framework that standardizes how any agent connects to RFT for training and evaluation.
Last March, Andrej Karpathy tweeted that there’s an “evaluation crisis,” that the standard industry AI benchmarks are no longer a good predictor of real-world performance.
EP seems designed to address this, to help developers run evaluations on their actual workflows.
For example, one core concept in EP is separating evaluation criteria (what constitutes “good” behavior) from the model producing it. That lets teams swap and compare how different models perform on the same, real-world tasks.
Can you walk through how you designed EP – and why?
First, some context. The closed model labs pay millions of dollars to buy simulated websites – perfect mocks of an e-commerce or airline ticketing system – to develop and test their models.
We don’t believe in that approach. These isolated environments rarely match what’s happening in production. Test databases might be incomplete, or the UIs behave differently.
At Fireworks, we help developers build evaluation suites that work with their existing agents, so their RL training environment matches production. This ensures consistency – across training, environment, and inference.
We also designed EP for developers without any machine learning backgrounds. For TypeScript and Rust developers, who had never touched Python and had built their agents in isolated, hosted environments.
We realized the only clean way to build evals for them is through observability – tracing agent outputs in production, labeling successes and failures, and feeding that directly into training. No need to package a working TypeScript agent into a Python container.
This “tracing-first” design means developers can build their agent however they want. We adapt to them.
Do you think EP grows demand for your own product? The theory being – as developers better evaluate how a model is performing, they demand more customization, then they turn to Fireworks to enable that.
Absolutely. I see buyers get more sophisticated when they run proper evaluations.
The more sophisticated the buyer, the more rational the buyer. And we believe open-source offers a more rational unit economic model.
Are there any new, cutting edge techniques you’re excited about?
Some, like Google’s new family of architecture Titans, which allows models to learn in production, on the fly.
But I’m honestly more excited about better data, rather than new techniques.
Before Fireworks, I was at Meta, moving ad models onto ASICs and GPUs for faster inference. I experimented with lots of new techniques and model architecture. My takeaway: better techniques only give you 20-30% of the gain. Most improvement comes from better data.
What are the gaps around data you still need to solve for?
Representativeness. In other words… Does your evaluation reflect what your customers care about?
Developers tend to over-index on things they personally notice, or failure cases they hit early on. Their evals rarely match exactly what their customers care about. And if your evals aren’t representative, you don’t get much value from RL.
The gap is translating what their customers want into concrete rubrics a language model can judge against.
So where are developers struggling? If they know what users want and can articulate their business model, why can’t they translate that into something a language model can interpret?
The hard part is moving developers from cardinal judgment (rating output on an absolute scale) to ordinal judgment (comparing several outputs on a relative basis).
For example, I’m a terrible judge of art. If you give me ten pieces and ask me to score each on a 1-10 scale, I can’t give consistent answers. But if you repeatedly show me two pieces and ask which I prefer, I’ll be much more consistent. I may not be able to articulate my internal rubric for scoring, but I can make reliable comparisons.
Language models work the same way. Setting up evaluations under a comparative framework is a big improvement.
Another place developers struggle is writing airtight rubrics. If you now force me to judge art on a 1-10 scale, I need to create a rubric without any loopholes.
That’s because LLMs are very creative. If you leave any ambiguities in your system, especially in production, they will exploit that. Writing evaluation criteria that close all those gaps is genuinely difficult, and that’s where we try to help developers.
04 | AI predictions in 2026
As we wrap, I’d love to do some rapid-fire questions.
Shoot!
Context management7 and state8 come up often as pain points in building AI applications. Are there any trends you’re excited about that solve for this?
As for context management, there have been a few recent papers around using images as a way to compress information, what’s called “contexts optical compression.”
Also, in production, we’re seeing agentic retrieval replace traditional RAG.9 This is a much more effective approach. Just like a human would say “I need the Q3 sales data” and then retrieve that information from the right file, the agent asks itself “What information do I need?” and retrieves it on-demand. This is aligned with what Claude is pushing with Skills – organizing tools into folders the agent can navigate, instead of shoving 200 tools into your context.
So agentic search is picking up, and I expect that will be a growing trend in 2026.
State, on the other hand, is more nuanced and application-specific. Sometimes “state” refers to whether you can replay an agent from the same point for error recovery. Sometimes it’s about how to do hand-offs between agents.
Agentic retrieval is happening everywhere, but state looks completely different across applications. My guess is there won’t be consolidation around state any time soon – it’s too context-specific.
What’s something in AI you think most people get wrong?
A big debate in Silicon Valley is around humanoid robots. Everyone agrees AI agents in, say, customer service and coding will make money. But people are 50/50 on whether humanoids will succeed.
I think it will be incredibly difficult for companies focused on humanoids to make money any time soon. There’s too much real-world complexity. And humanoids face competition from both actual humans and task-specific robots, which have much more efficient form factors for particular jobs.
What startup categories in AI are you most excited about over the next 2-3 years?
Without getting too self-promotional, AI infrastructure. There’s still so much to build.
Where in the infra stack specifically?
Companies doing semi-services, semi-evaluations. Those that can help businesses in a particular vertical digitize their processes, set up evaluation suites, and connect those to fine-tuning to improve models.
I like startups that don’t shy away from the fact that they do some services. That’s the right attitude. Customers are adjusting to it more because of the success of Palantir and their forward-deployed engineers.
Fully embracing that service component in order to help your customers solve a real problem – that’s critical.
Do you think those services will always come from a third-party, like Fireworks? Or for some segments, do see application providers offering this themselves, as part of their offering?
Third parties provide huge value today, but it depends on the vertical. In San Francisco, everyone says, “Of course you need evaluations.” But if you leave SF, it’s a completely different world. Most companies with the data – that could own their custom AI stack – have no idea how to get started.
There’s going to be a new BCG/McKinsey emerging from this. They’ll sit between infrastructure and applications, understanding intimately how agentic workflows should be evaluated, and helping customers build trust in the outputs from their own AI agents.
Trust is incredibly hard to build. New players who crack that trust layer can charge a lot of money for it.
This has been awesome. Thank you for the time.
Thank you for having me.
Open-source (or “open-weight”) models are those where the trained parameters (weights) are publicly released, allowing users to download, run, and customize them locally (unlike closed models, which are accessed via APIs).
Inference refers to running a trained model to generate outputs from new inputs. Unlike training, which is one-time or periodic, inference is an ongoing operational expense that scales with usage.
An evaluation suite is a set of tests and benchmarks tailored to measure how well an AI model performs on a specific use case. In other words, the metrics that define “success” for a particular software application.
Reinforcement fine-tuning (RFT) is a training technique that uses feedback on model outputs (i.e., distinguishing “good” responses from “bad” ones) to train models to perform better on specific tasks. This same technique is used by frontier labs like OpenAI and Anthropic to align base models with human intent, turning them into products like ChatGPT and Claude. Fireworks makes RFT accessible for developers for their custom applications and workflows.
Total cost of ownership (“TCO”) is the sum of all costs associated with software over its lifetime, including licensing fees, deployment, maintenance, support, training, and infrastructure. While open-source eliminates licensing fees, it can shift costs to internal engineering time for customization, integration, and support.
Defaults are best-practice configurations that ensure a model trains successfully without crashing or producing inaccurate results. These include numerical consistency (maintaining mathematical precision across different hardware to prevent errors that can degrade performance), tokenization (standardizing how text is converted into the precise numerical format the model expects), and GPU failure recovery (automatically saving progress and resuming training if a chip fails, preventing data loss).
Context management refers to what information an AI model can “see” when generating a response. LLMs have a fixed context window – a limit on how much text or data they can process at once. Developers must decide what to include (e.g., conversation history, relevant documents, user data) and what to leave out.
State refers to tracking where an AI agent is in a multi-step workflow – e.g., what has been completed, what it knows, and what it’s trying to accomplish.
Retrieval-augmented generation (RAG) is a technique where a system retrieves relevant documents and “stuffs” them into the AI’s prompt before it generates an answer. This can lead to bloated context windows and inefficient computation. In agentic retrieval, rather than dumping information upfront, the AI decides what to look for and when, pulling information on demand as it reasons through a task.