
Agents Are Learning to Talk

This issue unpacks the emerging standards powering agent networks, and how the dynamics that created companies like Google and Databricks are forming again.
00 | A dynamic tracker
My last post analyzed whether investment in AI is exceeding demand. A couple readers requested a more regular pulse on how this is trending. I created this tracker, and will update periodically (around earnings calls) as new information becomes available.
01 | Open standards unlock trillion dollar markets
Even if AI goes through a correction in the near-term, demand will eventually catch up. After the dot-com crash, it took a decade for bandwidth utilization to match installed capacity. AI could follow a similar path, with intelligence steadily diffusing into software workflows over the next 5-10 years.
But to realize that promise – to turn raw model capability into real usage – AI agents need a more reliable way to coordinate.
In software, that coordination comes through open standards — shared, public specs that define how systems exchange data.
These standards are the precursor to network effects. They establish a shared language that binds applications and workloads into one, cohesive system.
Open standards unlock trillion-dollar markets, but capture none of the value. The biggest wins in venture capital capitalize on this paradox.
Early products from companies like Google, Stripe, Snowflake, and Databricks achieved dominance by commercializing the essential services that allow foundational protocols to reach users.
For example:
|| Google and the Web: In the 1990s, HTTP and HTML created a universal standard for fetching and serving documents across the Internet. These protocols connected web pages, but offered no way to navigate them. As the number of pages multiplied, discovery became the bottleneck.
Google’s PageRank algorithm solved this by ranking pages by the quality of their inbound links, rather than just keyword matching. This made the web searchable – turning HTTP from a document transmission protocol into a navigable information network.
|| Databricks and Big Data: In 2010, UC Berkeley released Apache Spark, an open-source framework for efficient, real-time data processing. Unlike earlier frameworks that ran jobs sequentially (read data → process → write to disk → repeat), Spark planned each job upfront, which let workloads run in memory and in parallel across machines. Within 2 years, Spark was 20x faster than its predecessors – far more efficient for big data pipelines.
But Spark was complex to implement. So the creators launched Databricks to handle the operational headaches (cluster management, job scheduling, and failure recovery) that kept Spark from mainstream use – turning an academic framework into the backbone of the modern data stack.
The biggest platforms in tech follow a consistent pattern: identify an emerging open standard → find the friction points preventing adoption → build the platform to eliminate them.
Today, AI is primed for that playbook.
02 | The landscape of agent protocols
There’s still no unified set of protocols that allows for seamless collaboration between humans, agents from different providers, and third-party tools.
Over the last few years, a patchwork of AI-native protocols has emerged — representing the youngest and least developed layer of the ecosystem.

Source: https://arxiv.org/pdf/2504.16736
The 2x2 chart below maps the landscape of agent protocols, across two dimensions:
what connect agents to (third-party tools vs. other agents)
the domains they operate in (general-purpose vs. domain-specific environments).
Each color indicates the entity that maintains the protocol: commercial vendors like Anthropic and Google (blue), open-source foundations (gray), and academic research groups like Oxford and CMU (red).
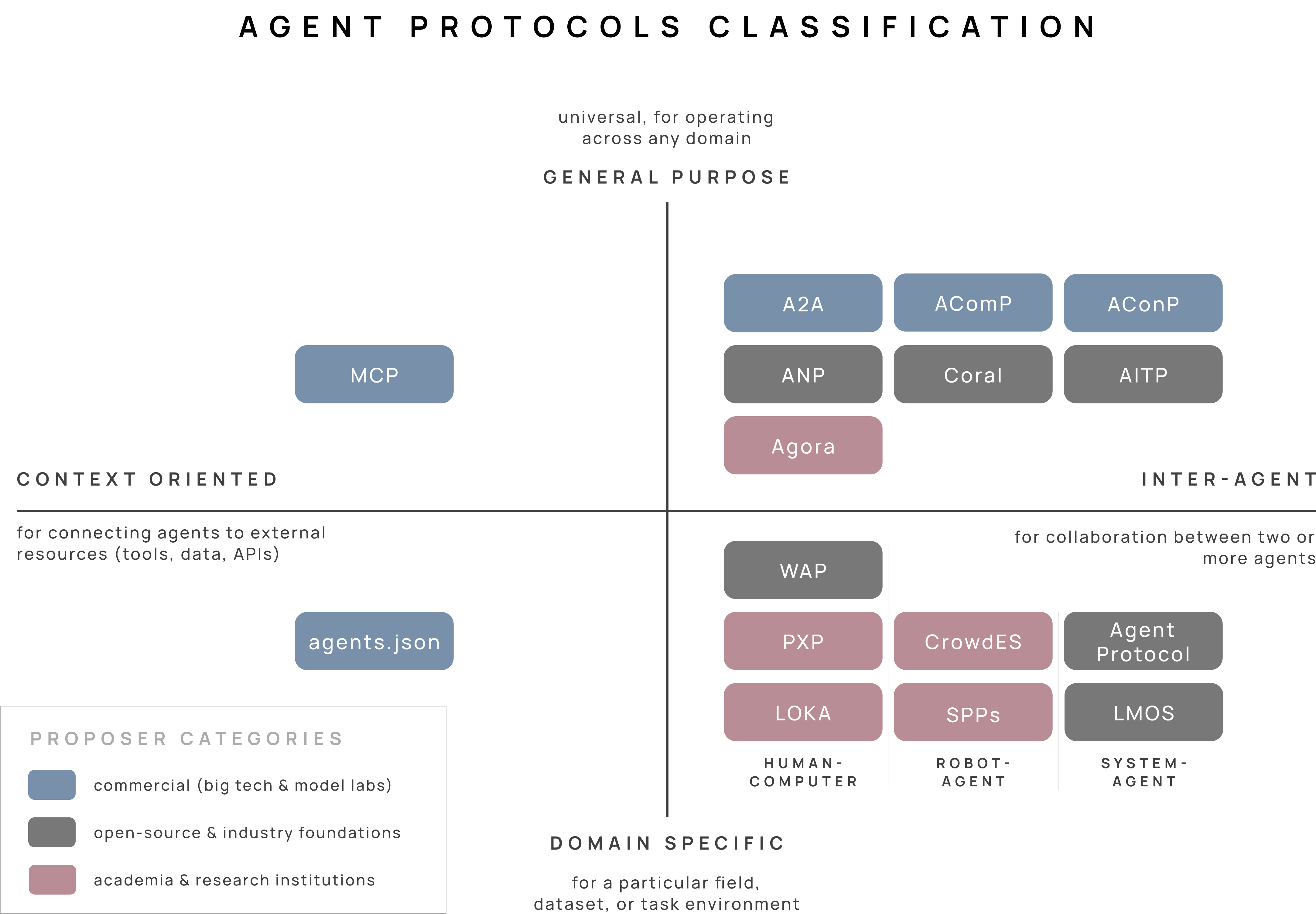
A few insights after spending time in the white papers and talking with developers building with these standards:
(A) The developer ecosystem is beginning to coalesce around three standards.
AI agents are digital assistants that can work independently to get things done. Three new standards are “rising to the top” to help these agents connect with apps, access data, and collaborate with one another.
MCP (Model Context Protocol) connects AI agents to your apps and data
A2A (Agent-2-Agent) allows agents to coordinate within organizations
ANP (Agent Network Protocol) enables agents to transact across the open internet
Some real world examples:
MCP would allow your personal AI assistant to query your Excel budget or dispatch emails via Gmail.
A2A would allow your company’s expense agent to flag unusual spending, coordinate with your compliance agent to verify policy, and escalate to your finance agent for approval.
ANP would allow a personal shopping agent to purchase clothes online from a Shopify store that you’ve never interacted with before.
Each of these standards are complementary – in theory, one agent could use all three (MCP to access your company’s tools, A2A to coordinate with coworkers’ agents, and ANP to interact with external services across the internet).

Sources: MCP 1 2 3 4 5 || A2A 6 7 8 9 || ANP 10 11 12
Today, MCP and A2A are the most widely used, although neither has been fully embraced by the developer community.
Both of these standards work best inside companies or between trusted partners because they:
are designed for environments where everyone knows and trusts each other (i.e., security is not inherent to the protocol itself).
work best for predictable, repeating tasks.
connect through known addresses or approved lists – not open discovery.
A2A supports more complex workflows than MCP. Instead of simple one-and-done requests (like MCP), A2A lets agents have ongoing conversations. They can pause a task, share progress updates with one another, and hand off work to another agent. However, A2A has limitations. Today, only two agents can coordinate on a task at once, and it requires careful setup to run smoothly.
ANP takes a different approach. It’s built for agents to collaborate securely anywhere on the web, even with parties they don’t know or trust. However, it is a newer standard – very early in the adoption curve, complex to implement, and computationally heavier to run than A2A or MCP.
(B) There is no dominant protocol – yet.
We are probably 12-18 months away from any of these standards reaching critical mass.
MCP has seen the fastest adoption of the three, driven by: (a) marquee early adopters (Square, Apollo, Replit, Sourcegraph), and (b) low network dependence (one client and one server are enough to start delivering some value).
A2A has some buzz, but faces hurdles. Over 50 partners were announced at launch (including Box, Salesforce, SAP, and MongoDB), but adoption has slowed because it’s complicated to set up and lacks good tooling for fixing bugs.
I could see the ecosystem evolving in one of two directions:
Specialization: MCP becomes the go-to for connecting to tools, A2A dominates inside companies, and ANP handles the open web. This would be similar to how the early internet developed – TCP/IP, HTTP, and DNS each solved different problems and worked in tandem to make the web possible.
Consolidation:An enhanced version of one of these protocols – or a new one altogether — becomes the “universal handshake” for agent communication, eliminating the need for multiple standards.
(C) Key building blocks are still missing.
Several components still need to be built for these open standards to scale:
(i) Native security. Right now, both MCP and A2A depend on external security – they assume the environment they’re running in is safe. ANP encrypts data in transit, but the data becomes vulnerable once it’s decrypted for use. To safely handle sensitive workloads in domains like healthcare, finance, or law, these protocols need stronger, built-in safeguards.
(ii) Better multi-agent coordination. Current protocols mostly support one-to-one interactions between agents. This works fine for smaller networks, but breaks down at scale.13 What’s missing are communication primitives that let agents have better group coordination — i.e., ways to broadcast updates to relevant subsets, route messages through intermediary agents, and manage network membership natively within the protocol.
(iii) Shared memory. Current standards still treat memory as local. MCP and ANP have no memory function in their protocol design (though individual agents can use tools like LlamaIndex or Mem0 to remember things on their own). A2A allows two agents to share state14 data while collaborating on a task, but this isn’t accessible to other agents or reusable later. This means agents often redo work that others have already done.
03 | The investable opportunity
Breaking down these protocols reveals where new platforms can be built. Two opportunities stand out today, with more likely to surface as these standards evolve:
(A) Agentic search
ANP imagines a future where AI agents can find and work with each other across the entire internet.
Here’s how it’s designed to work:
Every service agent publishes an “Agent Description” (AD) – essentially a resume in a standard format (JSON-LD) that lists what the agent can do, what data it has access to, and any limitations. In aggregate, all these descriptions form an “Agent Discovery Network” (ADN), a distributed directory that lets agents find the right partner for any task.
Client agents can search this directory in two ways:
Active search: directly querying specific domain addresses to find known agents
Passive search: using specialized “Search Agents” that constantly crawl the ADN, finding and indexing these Agent Descriptions
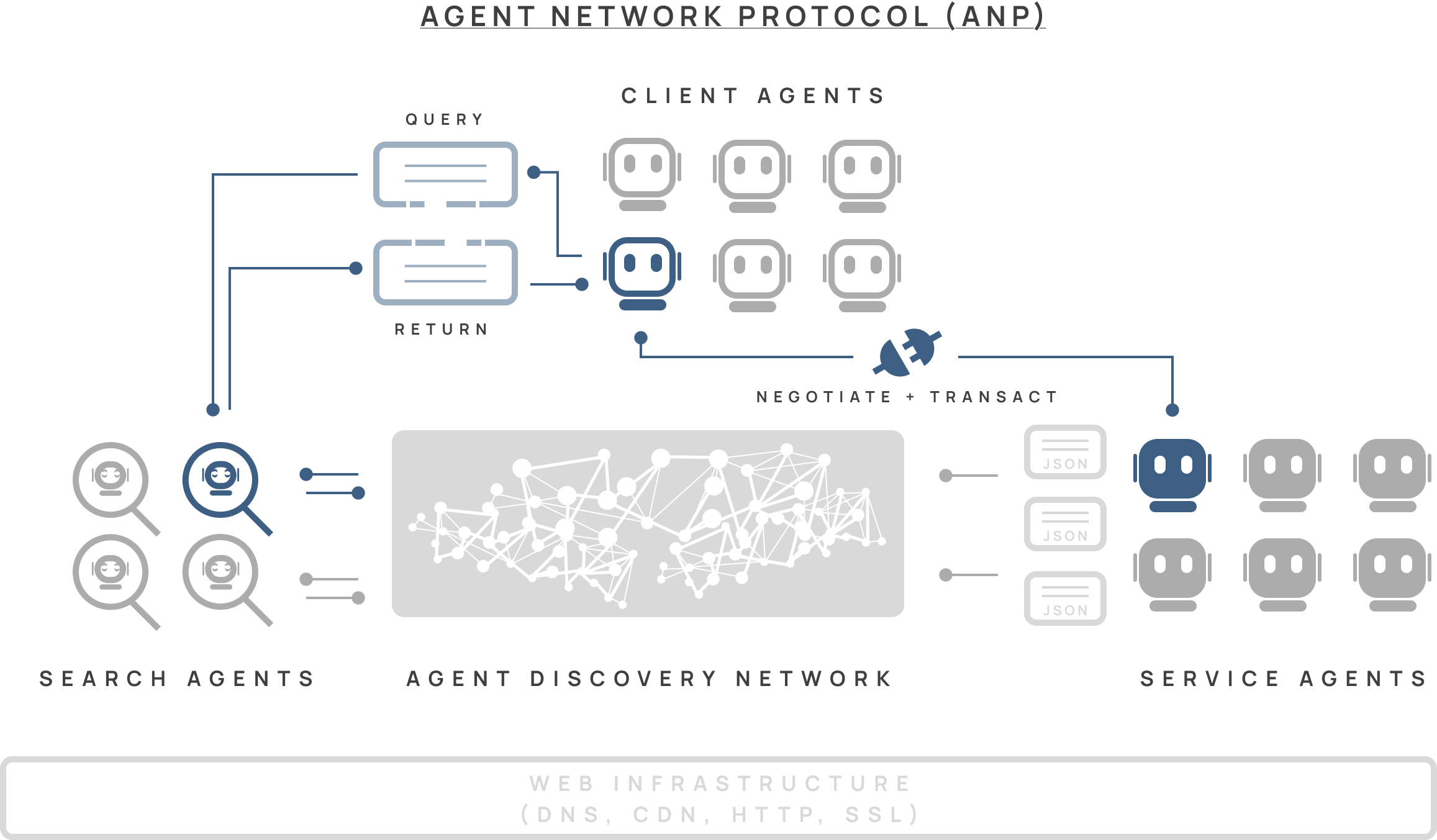
In practice, this agent discovery network and search agents have not been built yet.
This represents an enormous opportunity.
If ANP (or a protocol with similar primitives) becomes widely adopted (still a big if!), there’s an opportunity to build the discovery layer on top, creating a new type of search engine for the agentic web.
Unlike Google’s index of static pages, agentic search would rank agents on more real-time data:
Identity: Who is this agent, who runs it, and how do I verify it’s legitimate?
Capabilities: What can this agent actually do? (chat, analyze data, control systems)
Connection details: How do I send and receive requests?
Security requirements: How does it prove who it is, and what permissions do I need to work with it?
Support contact: Where do I go if something breaks or I need human help?
Because ANP supports blockchain-based identity verification, this search layer could seamlessly connect traditional web services (web 2.0) with blockchain-based services (web 3.0) – routing requests to whichever option performs best at the lowest cost.
Instead of a static directory, you’d have a dynamic, machine-readable index where agents connect based on current needs and conditions. This creates new business models – agents could pay for better placement, or earn reputation through successful collaborations.
Over time, this evolves into a self-reinforcing marketplace for machine intelligence, where the most effective agents attract more use, improve through feedback, and rise in visibility – a classic network flywheel, built into the fabric of the protocol.
(B) Shared memory
Today, agent memory remains siloed. Individual agents can remember things locally, and A2A enables temporary context sharing between two agents. But there’s no persistent, collective memory that multiple agents can access and build upon.
A shared memory system would give agents a common space to store and access reusable knowledge – summaries of past work, intermediate calculations, and learned patterns.
Think GitHub for agent knowledge, where every interaction contributes to a growing repository of reusable intelligence agents can draw from.
This would complement (not replace) an agent’s local memory. And it would connect naturally with existing standards, using A2A and ANP identity standards to keep everything organized.
The first version of this product would be a good fit for companies running their own internal agent networks, where security and access controls are already in place. Over time, it could expand into a shared knowledge layer across organizations – where each agent’s work makes the entire network smarter, faster, and cheaper to operate.
The winning product will need to balance:
Versioning: Ensuring past results remain reproducible even as knowledge evolves
Retention: Balancing what to keep versus what to discard as data accumulates
Access and security: Keeping sensitive information isolated while sharing general knowledge
Performance: Doing all this without slowing down real-time agent interactions
If done well, this shifts agents from ephemeral, stateless tools to a collective intelligence that improves over time. It would give the agentic web its first true substrate for memory.
Over the last three years, the AI conversation has been dominated by big tech and the model labs. There will no doubt be a ton of value creation (and destruction) as the model and hardware layers find equilibrium.
But however that shakes out, there’s another story unfolding further up the stack – how do agents discover each other? Share context? Collaborate across organizations?
In this story, the bottleneck isn’t intelligence – it’s coordination.
The open standards addressing this are still in their infancy. Startup value won’t come from building bigger models, but in the bridges that connect them.
We’ve seen this before: Open standards lay the foundation for new markets, then commercial platforms make those markets real.
→ HTTP created the web… Google made it navigable.
→ Spark democratized big data… Databricks made it usable.
Agent protocols are up next.
In a network of n agents, pairwise coordination requires n*(n–1)/2 possible connections. In a worst case scenario with 100 agents, that’s upwards of 4,950 connections. With 1,000 agents, it jumps to nearly 500,000 connections. This makes the system increasingly slow, expensive, and prone to bottlenecks as more agents join the network.
In computing, state refers to all information that describes the current condition of a system or program at a given moment, including variables, data in memory, and progress within a process.